ChatGPT先生に教わりながら「Transformerの肝」である「注意機構(Attention機構)」を可視化する
前回と前々回では機械学習アーキテクチャ「Transformer」を使って簡単な文章生成に挑戦しました。
ちょっと前までは、プログラミングで調べたいことがあるときは「Google先生」にお伺いを立てていたのですが、最近は「ChatGPT先生」にお伺いを立てることが増えました。
(ここでは ChatGPT に対して敬意を込めて「ChatGPT先生」と呼称しています。ChatGPT先生に問いかける時に出来るだけ敬語で問いかけるようにすると良い結果が出るようです)
今回は「Transformer」が「入力文のどの単語に注意しているのか」を”可視化”する方法を ChatGPT先生に聞きながら実装してみたいと思います。
注意機構(Attention機構)とは
#注意機構(Attention機構)は、Transformerに代表される自然言語処理や音声認識、画像処理などの分野で幅広く使用される機構です。
これは、モデルが与えられた入力の一部に重点を置くことができるようにする手法です。
通常は入力シーケンスの各要素には等しい重みが与えられますが、注意機構を使用すると、モデルはそれぞれの要素に対して異なる重みを与えることができ、これによりモデルが特定の情報により集中し、より良い予測を行うことができます。
Transformerではこの注意機構(Attention機構)が重要な役割を果たします。
使用する自然言語処理モデル
#今回使用する自然言語処理モデルは、前回も使用した「rinna/japanese-gpt2-medium」と、Transformerブーム(?)の火付け役となったであろう「BERT」を使っていきます。
使用するBERTモデルには「bert-base-uncased」を選択しました。
Jupyterなどでサンプルプログラムを実行させるときには、モデルがローカルにあった方が楽なので、モデルをローカルにダウンロードしておきます。
以下のコマンドでダウンロードすることができます。
transformers-cli download <モデルID>
例えば、bert-base-uncased をダウンロードする場合は、以下のように実行します。
transformers-cli download bert-base-uncased
Attentionの取り出し
#まず、テキストデータをトークン化して、Attention機構の出力を取り出していきます。
以下のように ChatGPT先生に取り出し方法を問いかけます。
自然言語処理モデルをロードして、テキストデータをトークン化してAttention機構の出力を取り出したいです
問いかけに対して、以下のような応答がありました。
提案されたプログラムを実行したところ、以下のようなワーニングが出力されました。

このワーニングについても ChatGPT先生に問いかけてみます。
問いかけに対して、以下のような応答がありました。

うーん、すいません。「ちょっと何を言ってるかわからない」(笑)・・・
ここはサラッと無視して先に進めます。
取り出したAttentionの中身を確認します。
中身はテンソルになっていました。

この数値の羅列を見るだけでは、どこに注意を払っているのかわからないですね。
Attentionの可視化
#Attention を取り出すことが出来たので、Attention を可視化してみたいと思います。
さっそく以下のように問いかけてみました。
Attentionを可視化する方法を教えてください
問いかけに対して、以下のような応答がありました。

なるほど、ヒートマップという方法があるのですね。
早速、次の問いかけをします。
Attentionをヒートマップで可視化するサンプルを教えてください
問いかけに対して、以下のような応答がありました。
提案されたサンプルプログラムを実行してみると(やっぱり)エラーが出ました。

想定内!(笑)
ChatGPT先生から提案される機械学習系のプログラムは”大抵の場合”失敗することがこれまでの経験でわかっているので、もう慌てません(笑)
テンソルのまま可視化処理をしたため、うまく可視化できなかったようです。
可視化ライブラリ(matplotlib)で可視化するためには、テンソルをNumpy配列に変換する必要があるようです。
修正方法について ChatGPT先生に問いかけながら、エラー部分を修正していきます。
(Google先生に聞いてもよいと思いましたが、ここは ChatGPT先生で通します)
結果として以下のプログラムを得ることが出来ました。
import torch
from transformers import BertTokenizer, BertModel
# BERTの事前学習済みモデルをロード
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
import seaborn as sns
import matplotlib.pyplot as plt
# テキストのトークン化
text = "I love natural language processing!"
tokens = tokenizer.encode_plus(text, return_tensors='pt', add_special_tokens=True, max_length=512, truncation=True)
# Attentionの取得
outputs = model(tokens['input_ids'], attention_mask=tokens['attention_mask'])
attention = torch.mean(outputs.attentions[-1], dim=1)[0].detach().numpy()
# ヒートマップの作成
sns.heatmap(attention, cmap="YlGnBu", xticklabels=tokenizer.convert_ids_to_tokens(tokens['input_ids'][0]), yticklabels=tokenizer.convert_ids_to_tokens(tokens['input_ids'][0]))
plt.show()
出力されたヒートマップは次のようになりました。
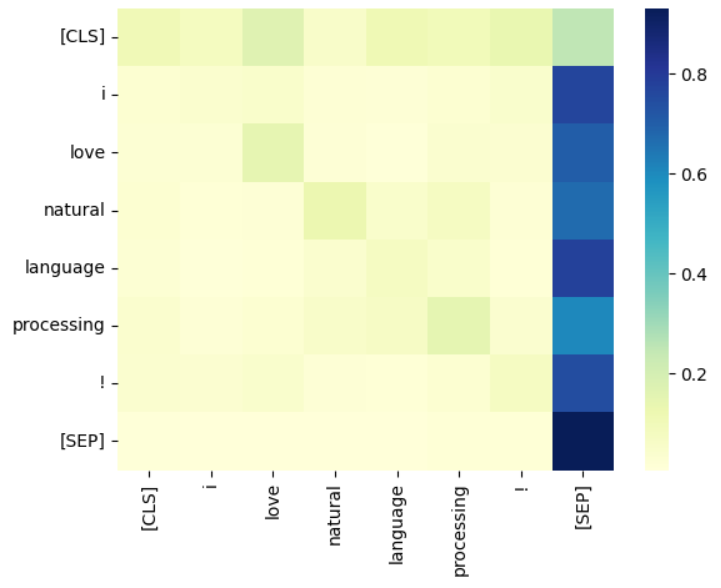
注意機構が”注意”している部分の色は明るくなるということらしいのですが、パッと見てよくわかりませんね。
プログラムの中の
attention = torch.mean(outputs.attentions[-1], dim=1)[0].detach().numpy()
の部分でAttetionの重みを計算していることはわかるのですが、この部分で何をしているのかを ChatGPT先生に問いかけます。
問いかけに対して、以下のような応答がありました。

プログラムの中の一部分だけを切り取って問いかけたのですが、しっかりとした応答になっていることがわかります。
折れ線グラフでの可視化
#「入力文の各トークンに対するAttentionの重み」に着目するならば、結果を折れ線グラフで可視化してもよいのでは?と思いました。
ChatGPT先生に折れ線グラフを使った可視化方法を問いかけました。
得られた結果は以下のプログラムです。
import torch
import matplotlib.pyplot as plt
from transformers import BertTokenizer, BertModel
# モデルとトークナイザーの準備
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
# 入力文を定義する
text = "I love natural language processing!"
# トークン化する
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.encode(text, return_tensors='pt')
# Attentionを取得する
outputs = model(input_ids)
attentions = outputs.attentions
attention = torch.mean(attentions[-1], dim=1)[0].detach().numpy()
# 折れ線グラフをプロットする
plt.plot(attention)
plt.xticks(range(len(tokens)), tokens, rotation=90)
plt.show()
先程のプログラムと比較して、Attentionを取得する部分が
outputs = model(input_ids)
attentions = outputs.attentions
のように変わっていますが、今のところ気にしないことにします。
今回のプログラムでは、モデルの取得時に引数として output_attentions=True を指定しています。
BertModel.from_pretrained(model_name, output_attentions=True))
この指定によって直接Attentionが取得できるようになっているようです。
出力された折れ線グラフは次のようになりました。
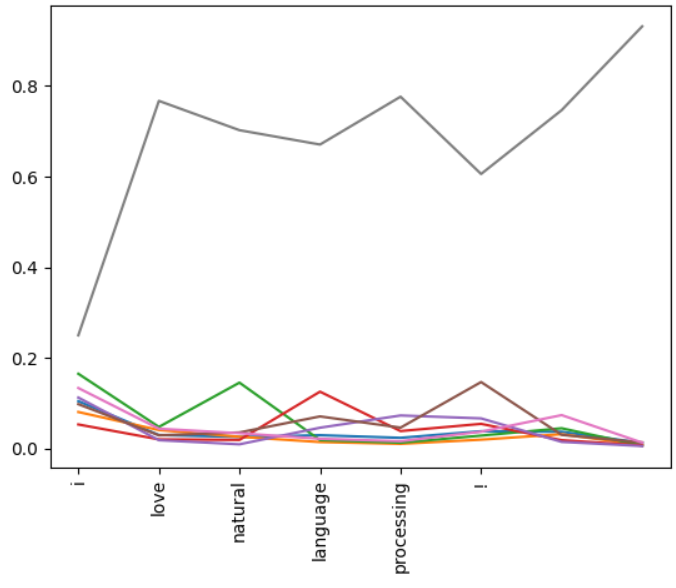
英単語の「love」「processing」で数値が高くなっている”ような”気がします。
わずかですが単語の”注意度”に差が見られました。
日本語で挑戦してみる
#モデルを「rinna/japanese-gpt2-medium」に変更し、同様の手順でAttentionを可視化してみます。
日本語を含む文章を可視化するとグラフの中の日本語出力に文字化けが生じたので、以下のようにして”フォント”を指定しました。
(筆者の環境はWindows10です)
import matplotlib as mpl
plt.rcParams['font.family'] = 'MS Gothic'
自然言語処理モデルに「rinna/japanese-gpt2-medium」を使用することを指定して ChatGPT先生に問いかけをしました。
しかし、提案されたサンプルをそのまま動かしても動きません(笑)
何度も試行錯誤(と言う名の「禅問答」)を繰り返し、次のプログラムを得ることが出来ました。
(途中で数回Google先生にお伺いを立てました)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
model = AutoModelForCausalLM.from_pretrained(model_name, output_attentions=True)
input_text = "今日はカレーライスを食べました。明日はラーメンを食べようと思います。"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# Attentionを取得する
outputs = model(input_ids)
attentions = outputs.attentions
# 言語モデルに入力された文に対するAttentionの重みを取得
attention = torch.mean(attentions[-1], dim=1)[0].detach().numpy()
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
plt.rcParams['font.family'] = 'MS Gothic'
fig, ax = plt.subplots(figsize=(10, 10))
im = ax.imshow(attention)
ax.set_xticks(range(len(tokenizer.tokenize(input_text))))
ax.set_yticks(range(len(tokenizer.tokenize(input_text))))
ax.set_xticklabels(tokenizer.tokenize(input_text))
ax.set_yticklabels(tokenizer.tokenize(input_text))
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")
for i in range(len(tokenizer.tokenize(input_text))):
for j in range(len(tokenizer.tokenize(input_text))):
text = ax.text(j, i, "{:.2f}".format(attention[i, j]),
ha="center", va="center", color="w")
plt.show()
出力されたヒートマップは次のようになりました。
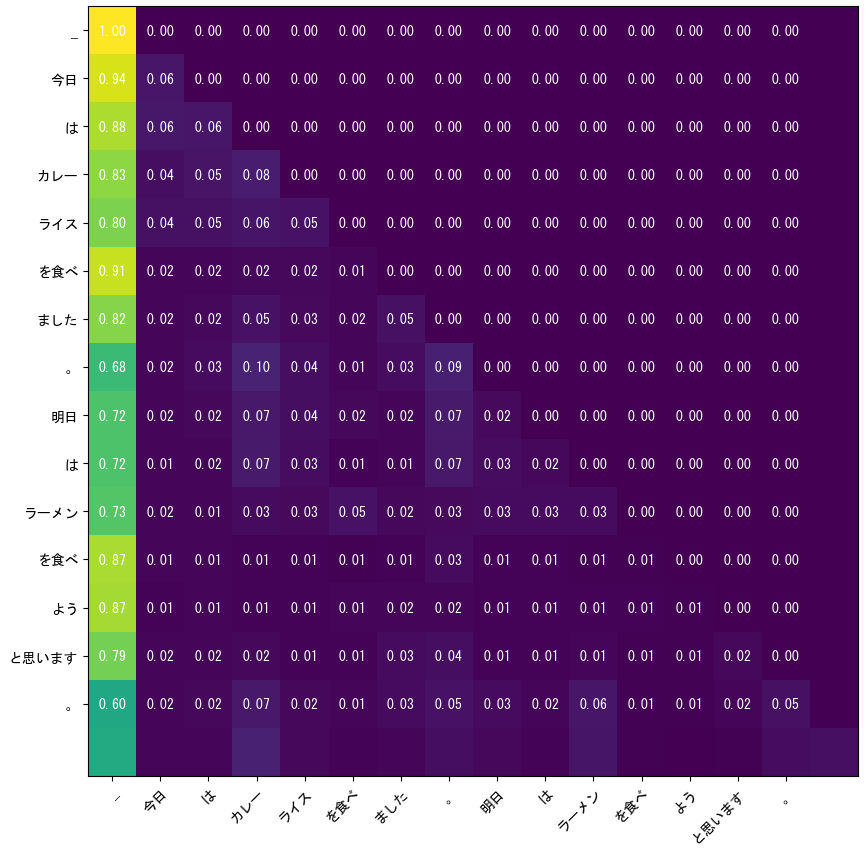
何となくですが「食べる」の文字に注意が向いているように見えます。
ちなみに3Dプロットライブラリで可視化した結果が以下です。
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 3Dグラフを作成する
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# ノードを配置する
x, y, z = [0], [0], [0]
for i in range(len(attention)):
for j in range(len(attention[i])):
x.append(j+1)
y.append(i+1)
z.append(attention[i][j] * 100)
# ノードをプロットする
ax.scatter(x, y, z, s=100, alpha=0.5)
# グラフを表示する
plt.show()
3Dグラフでの可視化結果は次のようになりました。
うーん・・・、3Dにする意味が無かったですね。
普通に折れ線グラフで可視化してみましょう。
tokens = tokenizer.tokenize(input_text)
# 折れ線グラフをプロットする
plt.plot(attention)
plt.xticks(range(len(tokens)), tokens, rotation=90)
plt.show()
折れ線グラフでの可視化結果は次のようになりました。
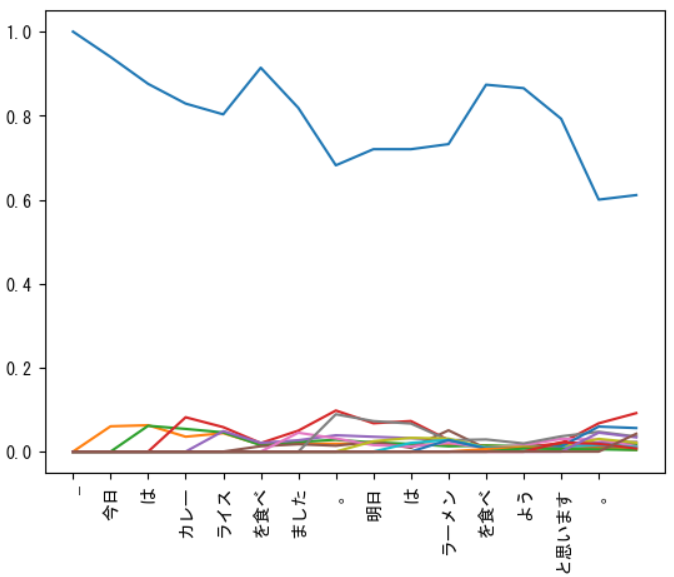
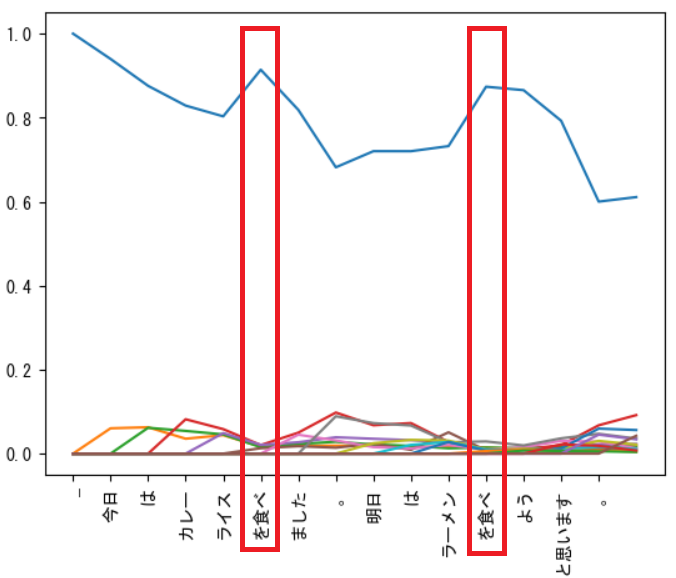
グラフを見てみると「食べる」という単語に注意が向いているように見えます。
シャーロック・ホームズにはなれないが、ワトソン博士くらいには
#ここまで ChatGPT先生とお付き合いさせて頂いてきて、私が得た感想は
まだシャーロック・ホームズにはなれないが、ワトソン博士くらいにはなれるかな
です。
シャーロック・ホームズのように完璧に問題を解決してくれることはないが、ワトソン博士のように「知っていることを丁寧に教えてくれる」役として十分に活用できるように思いました。
ちなみに、今は覚えている人も少なくなったとは思いますが、Windowsには「ワトソン博士」がいました。
「Windowsに含まれているアプリケーション・デバッガ」です。
昔はワトソン博士に色々とお世話になりました。
また、診断ツールには「シャーロック」という名前がついていたようです。
これからどんどん ChatGPTを含むAI技術が進化していくと、いずれはワトソン博士からシャーロック・ホームズに進化するかもしれません。
筆者の年齢はアラカンですが、今の進化スピードなら”シャーロック・ホームズ”に生きているうちに会えるかもしれないと密かに期待している今日この頃です。
今後は他のTransformersたちも紹介していきたいと思います。