AWS Lambdaのレスポンスストリーミングを使ってChatGPTっぽいUIにする
2023-04-07にAWS Lambdaのレスポンスストリーミングのサポートが発表されました。
AWS Lambdaでは、同期型のHTTP通信はリクエスト・レスポンスモデルのみで、Lambdaの実行時間に比例してユーザーへの応答時間も長くなります。
今回サポートされたレスポンスストリーミングでは、部分的でもレスポンスの準備ができ次第すぐに返せますので、UXはかなり改善しそうです。
また、記事によるとレスポンスストリーミングでは、レスポンスサイズの制約も6MBから20MB(ソフトリミット)へと緩和されるとのことです[1]。
今回は、このLambdaレスポンスストリーミングを使って、OpenAIのChat Completion APIのレスポンスをChatGPT風に段階的に表示されるようにしてみたいと思います。
なお、ここで実装したソースコードはGitHubレポジトリに格納しています。
SAMプロジェクトのセットアップ
#今回は冒頭の記事で使用されているAWS SAMでプロジェクトをセットアップします[2]。
SAMのCLIで用意されているinitコマンドで以下を実行します。
sam init --name lambda-response-stream-sample \
--app-template hello-world-typescript --runtime nodejs18.x
現時点でレスポンスストリーミングがサポートされているマネージドランタイム環境はNode.jsのみです。このためランタイム環境はnodejs18.xを選択しました。
また、テンプレートはシンプルなTypeScriptプロジェクト(hello-world-typescript)を指定しました。
続いて必要なライブラリを依存関係に追加します。
npm install openai @aws-sdk/client-ssm
OpenAI APIの公式ライブラリに加えて、AWS SSMのSDKも追加しました。
これは、SSMパラメータストアに保存したOpenAI APIのAPIキーを取得するために必要なものです[3]。
レスポンスストリーミングでLambda関数を実装する
#続いてLambda関数の実装です。SAMのinitコマンドで生成されたapp.tsを以下のように書き換えました。
import * as AWS from '@aws-sdk/client-ssm';
import { Configuration, OpenAIApi } from 'openai';
import { IncomingMessage } from 'http';
import { pipeline as pipelineSync, Transform, TransformOptions } from 'stream';
import { promisify } from 'util';
const pipeline = promisify(pipelineSync);
// OpenAIのストリームレスポンスをChatメッセージに変換するカスタムTransformer
class ChunkTransformer extends Transform {
constructor(options?: TransformOptions) {
super(options);
}
_transform(chunk: Buffer, encoding: BufferEncoding, callback: (error?: Error | null, data?: any) => void): void {
console.log(chunk.toString());
const payloads = chunk.toString().split('\n\n');
for (const payload of payloads) {
if (payload.includes('[DONE]')) {
break;
}
if (payload.startsWith('data:')) {
const data = payload.replaceAll(/(\n)?^data:\s*/g, '');
try {
const delta = JSON.parse(data.trim());
this.push(delta.choices[0].delta?.content || '');
} catch (error) {
console.log(error);
}
}
}
callback();
}
}
// SSMパラメータストアからAPIキーを取得
const ssmClient = new AWS.SSM({});
const ssmParam = ssmClient.getParameter({ Name: '/openai/api-key', WithDecryption: true });
// Lambdaイベントハンドラー本体
export const lambdaHandler = awslambda.streamifyResponse(async (event, responseStream, context) => {
const json = JSON.parse(event.body || '{}');
if (!json.message) {
responseStream.write('no message');
responseStream.end();
return;
}
try {
// OpenAI APIの実行
const apiKey = (await ssmParam).Parameter?.Value || '';
const configuration = new Configuration({
apiKey
});
const openai = new OpenAIApi(configuration);
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [{
role: 'user',
content: json.message
}],
max_tokens: 1024,
temperature: 0.7,
stream: true // enable stream
}, {
responseType: 'stream' // axios option(required)
});
// Node.jsのPipelineに連携
const stream = response.data as unknown as IncomingMessage;
await pipeline(stream, new ChunkTransformer(), responseStream);
} catch (err) {
console.log(err);
responseStream.write('エラーが発生しました!');
responseStream.end();
}
});
ポイントはイベントハンドラーで、awslambda.streamifyResponse(...)内に関数をラップしているところです。
最初はこのawslambdaが何者か分からず混乱しましたが、LambdaのNode.jsランタイム環境に組み込まれているもののようです。
公式ドキュメントには以下のように記述されています。
Wrap your function with the awslambda.streamifyResponse() decorator that the native Node.js runtimes provide.
ここでTypeScriptの型チェックでエラーにならないように、以下のd.tsファイルを用意しました。
import { APIGatewayProxyEvent, Context, Handler } from 'aws-lambda';
declare global {
namespace awslambda {
function streamifyResponse(f: (event: APIGatewayProxyEvent,
responseStream: NodeJS.WritableStream,
context: Context) => Promise<void>): Handler;
}
}
この関数シグニチャで重要なのはresponseStreamです。
レスポンスストリーミングは通常のLambda関数とは違い、ここに結果(チャンク)を書き込んでいくスタイルになります。
これのやり方として冒頭の記事や公式ドキュメントでは、Node.jsのpipelineを使うことを推奨しています。
we recommend that you use pipeline() wherever possible. Using pipeline() ensures that the writable stream is not overwhelmed by a faster readable stream.
これに従い、以下のストリームパイプラインを構築しました。
- 入力: OpenAI APIのストリームレスポンス(streamオプション有効化指定) ※下記コラム参照
- 変換: ストリームレスポンスのチャンクをチャットメッセージ変換(ChunkTransformer)
- 出力: Lambdaレスポンスストリーミング(responseStream)
本題から外れるので詳細は省略しましたが、OpenAI自体もstreamオプションを有効にすることでChatGPTのように段階的にチャンクメッセージを受け取ることができます。
各チャンクは以下のようにdata:に続いてJSONメッセージが設定されます。終了時にはJSONの代わりに[DONE]が出力されるようになっています。
- 最初のチャンク
data:
{
"id": "chatcmpl-78ILvs4XFg967lP17phrjVWCpRssF",
"object": "chat.completion.chunk",
"created": 1682211527,
"model": "gpt-3.5-turbo-0301",
"choices": [
{
"delta": {
"role": "assistant"
},
"index": 0,
"finish_reason": null
}
]
}
- 2番目以降のチャンク
data:
{
"id": "chatcmpl-78ILvs4XFg967lP17phrjVWCpRssF",
"object": "chat.completion.chunk",
"created": 1682211527,
"model": "gpt-3.5-turbo-0301",
"choices": [
{
"delta": {
"content": "Hello"
},
"index": 0,
"finish_reason": null
}
]
}
- 最後のチャンク
data:
{
"id": "chatcmpl-78ILvs4XFg967lP17phrjVWCpRssF",
"object": "chat.completion.chunk",
"created": 1682211527,
"model": "gpt-3.5-turbo-0301",
"choices": [
{
"delta": {},
"index": 0,
"finish_reason": "stop"
}
]
}
data: [DONE]
今回カスタムで作成したChunkTransformerは、この形式のレスポンスをチャットメッセージのチャンクとしてLambdaのresponseStreamに流れるようにしています。
Lambda関数をビルド・デプロイする
#それでは、これをデプロイします。
ここではSAMの初期化で生成されたtemplate.yamlを以下のように修正しました。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: lambda-response-stream-sample
Resources:
# Lambdaの実行ロール
ChatFunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: SSMOpenAIApiKeyRead
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- "ssm:GetParameter"
Resource:
- !Sub "arn:aws:ssm:*:${AWS::AccountId}:parameter/openai/api-key"
Path: "/"
# Lambda関数本体
ChatFunction:
Type: AWS::Serverless::Function
Properties:
Role: !GetAtt ChatFunctionRole.Arn
CodeUri: chat/dist
Handler: app.lambdaHandler
Runtime: nodejs18.x
Timeout: 60
Architectures:
- x86_64
FunctionUrlConfig:
AuthType: NONE
InvokeMode: RESPONSE_STREAM # LambdaレスポンスストリームON
Cors:
AllowCredentials: true
AllowMethods: ["POST"]
AllowOrigins: ["*"]
AllowHeaders: ["*"]
Outputs:
ChatApi:
Description: "Chat Lambda Function URL"
Value: !GetAtt ChatFunctionUrl.FunctionUrl
ChatFunction:
Description: "Chat Lambda Function ARN"
Value: !GetAtt ChatFunction.Arn
ポイントは、ChatFunctionのFunctionUrlConfigです。
現時点では、レスポンスストリーミングはAPI GatewayやALB(Application Load Balancer)をサポートしていません。ここではLambda Function URLを有効にします。
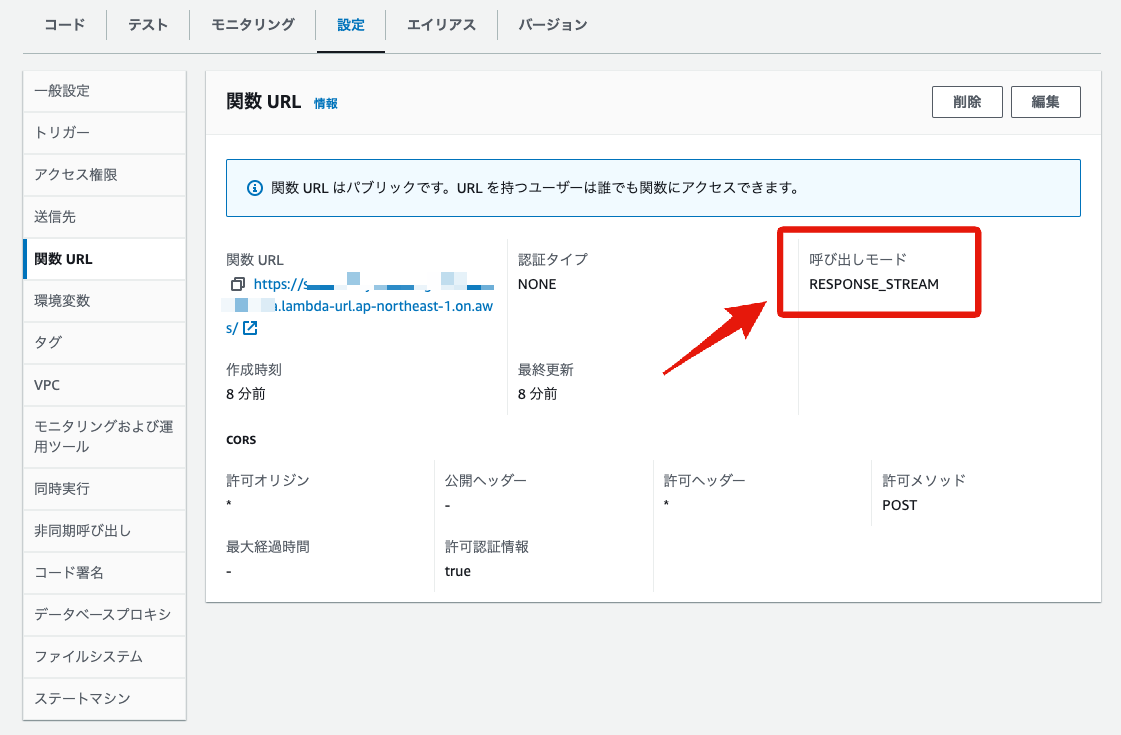
このFunctionUrlConfigのInvokeModeにRESPONSE_STREAMを指定することで、Lambdaのレスポンスストリーミングが有効になります。
また、この後でローカル環境で動作する簡単なUIも作成しますので、CORSの許可設定もしておきます。
続いてビルドですが、当初はSAMのesbuildサポートを使うつもりでしたがうまく動きませんでした。
ここでは、個別にesbuildでバンドルする方法を使います(やり方に問題があったかもしれませんので、後日リトライしてみようと思います)。
以下のesbuild用のスクリプト(build.js)を別途用意しました。
require('esbuild').build({
entryPoints: ['app.ts'],
bundle: true,
minify: true,
sourcemap: true,
outfile: 'dist/app.js',
target: 'node18',
platform: 'node'
}).catch((e) => console.log(e) && process.exit(1));
Lambda関数本体のapp.tsをエントリーポイントとしてdist/app.jsにバンドルします。これがLambdaのデプロイ対象になります。
以下スクリプトでアプリケーションをバンドルし、SAMテンプレートをビルドします。
# Lambda関数ソースコードディレクトリに移動
pushd chat
# esbuildでバンドル
node build.js
# プロジェクトルートに戻る
popd
# SAM CLIでビルド
sam build
最後にデプロイします。
sam deploy
実行が終わるとLambda関数がデプロイされます。
以下はAWS管理コンソールから見た状態です。
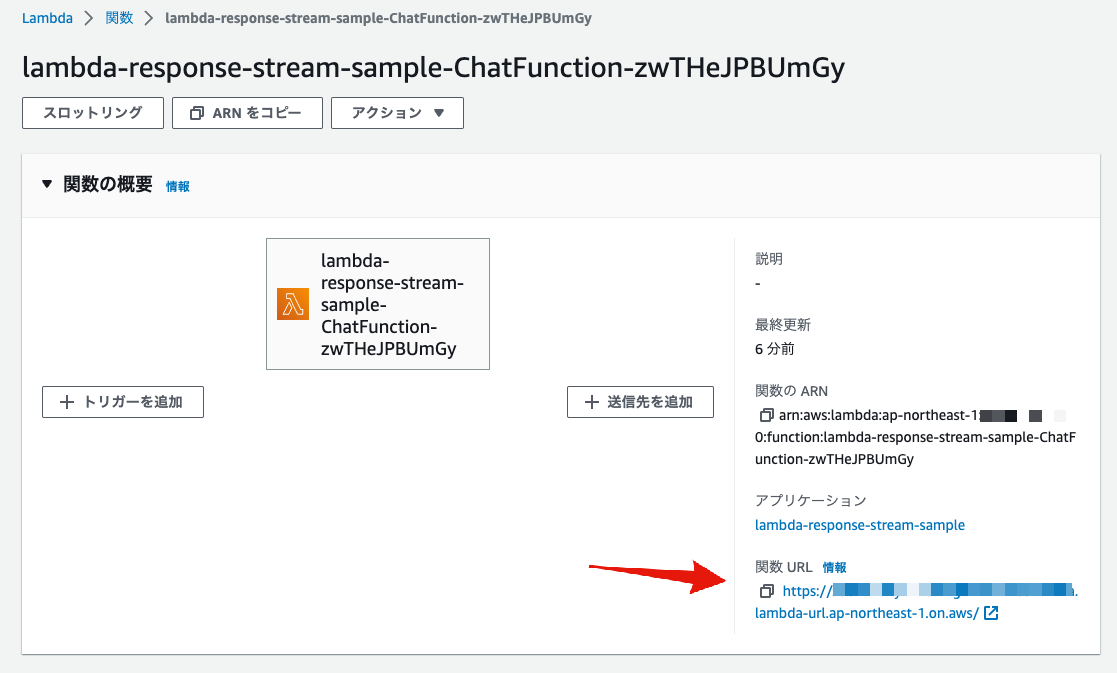
関数URL(Lambda Function URL)のエンドポイントが作成されているのが分かります。
また、関数URL自体の設定を見てみると、呼出モード(InvokeMode)にテンプレートで指定したRESPONSE_STREAMが設定されていることが確認できます。
試しにcurlでリクエストを送ってみました。
curl https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/ \
-H 'Content-Type:application/json' -d '{"message": "こんにちわ!あなたは誰ですか?"}'
> こんにちは!私はAIアシスタントのGPT-3です。あなたのサポートになります。
これくらいのレスポンスだと、ストリーミングしている感はありませんが問題なさそうです。
レスポンスストリーミング向けのUIを作成する
#ここで、レスポンスストリーミングを活用したUIを作成します。今回はNuxt3を使います。
以下でプロジェクトを作成します。
npx nuxi init nuxt-app
cd nuxt-app
npm install
今回はサンプルなので、ページコンポーネントは作成せずapp.vueを以下のように修正しました。
<script setup lang="ts">
const message = ref('');
const response = ref('');
const ask = async () => {
response.value = '';
const config = useRuntimeConfig()
const stream = await $fetch(config.public.API_ENDPOINT, {
method: 'POST',
body: { message: message.value },
responseType: 'stream'
});
const reader = (stream as ReadableStream).getReader();
let done = false;
const decoder = new TextDecoder();
while (!done) {
const { value, done: isDone } = await reader.read();
if (isDone) {
done = true;
break;
}
const newData = new Uint8Array(value);
response.value += decoder.decode(newData);
}
}
</script>
<template>
<div>
<textarea v-model="message" cols="50" rows="5" style="display: block;margin-bottom: 5px"></textarea>
<button @click="ask">送信!!</button>
<div style="margin-top: 5px">{{ response }}</div>
</div>
</template>
送信ボタンがクリックされたら、Nuxt3の$fetch APIで先程のLambda関数をstreamタイプで呼出しています。
このレスポンスはストリームとなりますので、レスポンスが完全に終了するまでresponse変数に追記していきます。
このresponse変数はref関数でリアクティブにしているので、更新がある度に最新化され、ChatGPTのような見た目になるはずです。
設定情報(RuntimeConfig)で使っているAPI_ENDPOINTはLambda関数のエンドポイントです。
nuxt.config.tsで用意しています。
export default defineNuxtConfig({
runtimeConfig: {
public: {
API_ENDPOINT: 'https://xxxxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws'
}
}
})
もちろんここには先程デプロイしたLambda関数のURLを設定します。
後は実行するだけです。開発モードでローカルから実行します。
npm run dev
ブラウザからhttp://localhost:3000/にアクセスします。
以下動画です。
ChatGPTのように、段階的にメッセージが追記されている様子が分かりますね。
最後に
#今回は結構試行錯誤しながらやりましたが、無事Lambdaのレスポンスストリーミングを活用したUIを実装できました。
現時点で利用できる環境は限られますが、レスポンスストリーミングは実行時間が長いもの以外でも、レスポンスサイズが大きくなりがちなファイルダウンロード等、アイデア次第で用途は広そうです。
今後の動向をチェックしていきたいなと思いました。
参考資料