NewSQL分散データベースTiDBをハンズオンつきで紹介してみる
この記事は夏のリレー連載2024 8日目の記事です。
はじめに
#こんにちは、ビジネスソリューション事業部の山下です。
分散データベースと聞いて、難しそうとか管理が面倒そうとか、スゴそうとかそんなことを考える人も少なくないと思います。
今回の記事では最後のイメージ以外は払拭できるように、 NewSQLの分散データベースシステムであるTiDBを紹介させていただきたいと思います。ちなみにTiの読み方は「タイ」です。
TiDBとは
#TiDBはOSSのデータベース管理システムであり、PingCAP社によって分散型のNewSQLとして開発されました。
MySQL互換のSQLプロトコルをほぼ利用でき、スケーラビリティと一貫性を両立しています。
PingCAP社のGithubページはこちらです。
ツール系のリポジトリに関してはApache License 2.0となっています(2024年8月1日現在、一部MITライセンスのものがあります)。
TiDB自体は複数のサービスの集合体なので、1つのリポジトリにあるわけではありません[1]。
実装自体はGo言語とRustで記述されています。
TiDBの特長
#TiDBの特長として、往々にして以下のものが挙げられます。
-
強力な一貫性:
分散トランザクションをサポートしており、複雑なトランザクション処理が可能。 -
水平スケーラビリティ:
ノードを追加すること容易にスケールアウトでき、書き込みのスケールアウトにも対応している。 -
可用性:
高可用性のアーキテクチャを採用しているため、障害時でもサービスを継続的に提供できる。
また、複雑な操作を必要とせずともダウンタイムを最小に抑えて復旧できる。 -
分析処理への対応:
列指向型のストレージを内包しているため、分析処理も効率的にこなせる。
また、トランザクション処理(OLTP)と並行して分析処理(OLAP)も行える。 -
MySQL互換性:
TiDBはMySQLプロトコルと互換性があり、MySQLクライアントで通信可能である。
そのため、既存のデータベースでMySQLを使っていれば、ほぼそのまま移行できる。
TiDBのアーキテクチャの紹介
#ここでは、分散システム全体のアーキテクチャについて説明させていただきます。
以下がTiDBアーキテクチャ図となります[2]。
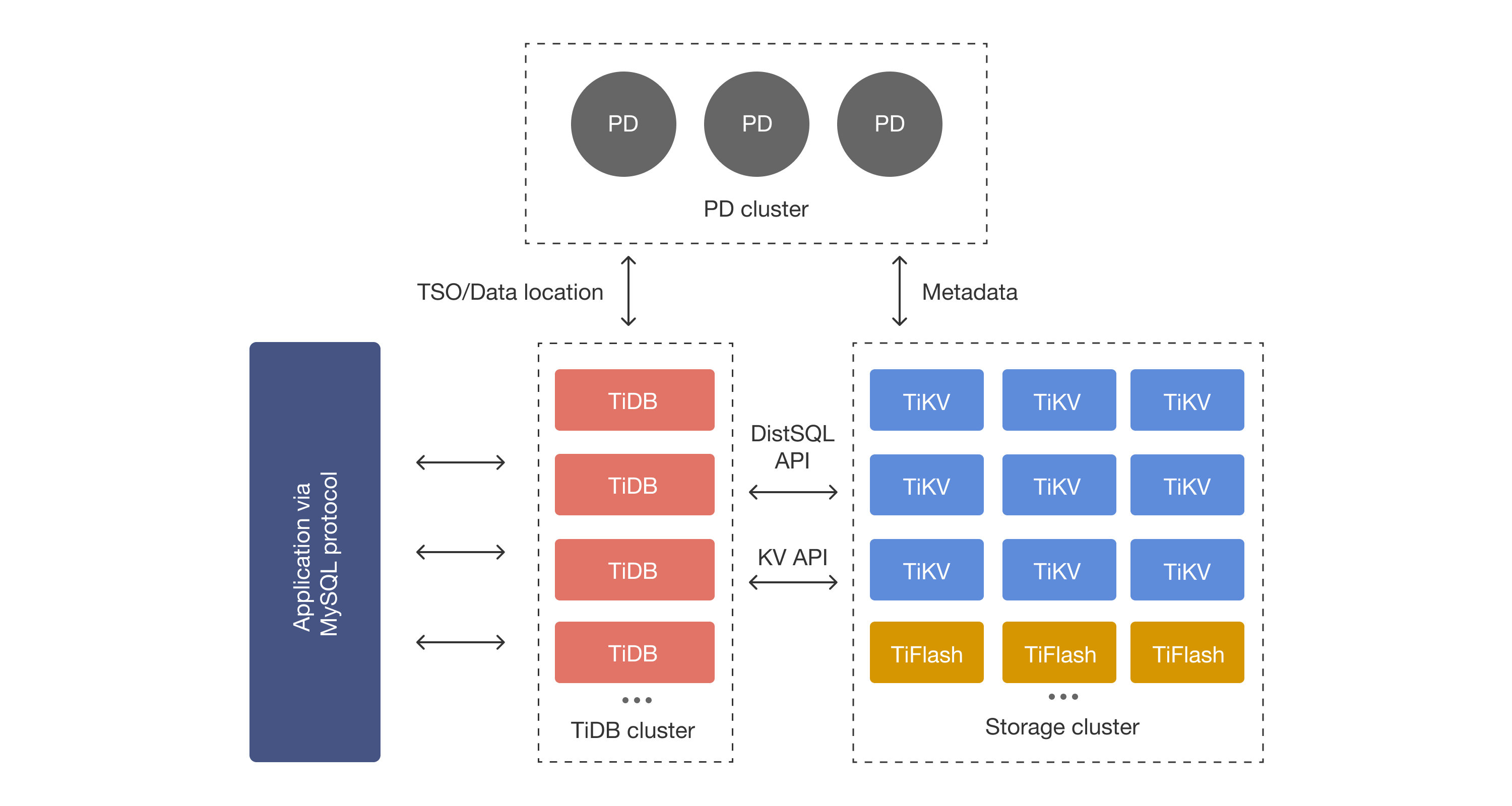
TiDBの構成は非常にシンプルな構成で、以下の通りになります。
- TiDB Cluster (MySQLクライアントと直接やり取りするクラスタ)
- Storage Cluster (ストレージクラスタ)
- Placement Driver Cluster (管理クラスタ)
最低限上記のことが頭に入っていればハンズオンは問題なく実行できます。
なるべく早く試したいという方はハンズオンまで飛ばしてしまっても構いません。
1. TiDB Cluster
#TiDB ClusterはクライアントサービスからのSQLを受け付けるクラスタです。
1.1. TiDB
#TiDB ClusterにはTiDBノードが属しています。
TiDBノードが窓口となってクライアントからのSQLリクエストを受け付けます。
TiDBのストレージ層の実体は、あくまで巨大なキーバリューマップです。TiDBノードはクライアントからのSQLを受け付けて、キーバリューマップに対するクエリに変換する役割を果たしています。
TiDBで使われているSQL文のParserもオープンソースとなっています。TiDBはMySQL互換を謳っていますが、具体的にどの関数が対応しているのかを知りたい場合には以下のリポジトを覗いてみてください(Parserそのものはparser.yです)。
TiDBでは、他のDBMS同様に、SQL文をパースした後に統計情報なども参考にして物理的な実行計画に変換します。2024年8月現在、System Rモデルと呼ばれるものを参考にして実行計画が決定されています。
詳細については以下のリンクを確認してみてください。
2. Storage Cluster
#Storage Clusterに属するノードとして、TiKVとTiFlashが存在します。
2.1. TiKV
#TiKVの実体は、巨大なMapストレージとして機能する分散型キーバリューストアです。
TiKVノードはRaftアルゴリズムと呼ばれる分散合意アルゴリズムによってデータを同期しています。
RaftアルゴリズムにはLeaderとFollowerという概念があり、FollowerがLeaderの値を追従するという形式を取ります。
分散合意アルゴリズムの一種であり、LeaderとFollowerが状況によって動的に入れ替わりながら、各ノードのもつ情報が同期されるという形式を取ります。
参考ページとして以下のものを掲載させていただきます。
TiKVはストレージにKey Valueデータを保存しているわけではありません。RocksDBと呼ばれるLSMツリーストレージエンジンでデータ管理を行なっています。
データそのものだけではなくRaftによる制御に関わる情報もRocksDBに保管されています。前述のRaftアルゴリズムと併せて、読み書き両方のスケールアウトに対応できるような同期処理を可能としています。
2.2. TiFlash
#TiKVがいわゆる行指向のストレージ形式を持つノードでした。一方、TiFlash Serverは、列指向のストレージ形式を持つノードです。
トランザクション処理と分析処理を同時にできることはPingCAP社公式においてもTiDBの強みとされており、この分析処理はTiFlashにより実現されています。
TiFlashはTiKVを同期させているRaftと独立して動いているわけではなく、Raftアルゴリズムのエコシステムにきちんと組みこまれています。
具体的にはRaft learnerと称されています。
3. Placement Driver Cluster
#Placement DriverはKVノード群を管理するクラスタのことです。
3.1. PD Server
#Placement Driver (PD)ノードは、分散システムにおけるクラスタ管理の中枢を担うノードであり、TiDBにおいて重要な役割を果たします。
PDノードは主に以下の2つの処理により、TiKVクラスターを管理します。
- クラスタから情報を収集
- TiKVノードのコントロール(再配置を含む)
Raftアルゴリズムは前述のQiita記事で示しているように、Crash-Recovery耐性は持っていても、Byzantine(ビザンチン)耐性を持ちません。
すなわち、ノードがスケジュールから外れるような勝手なふるまいを始めた場合には対応できなくなります。そのため、KVノードの動きを厳密に管理する機構が必要となるようです。
参考として以下のリンクを掲載します。
TiDBを体験してみよう
#1. tiup playgroundについて
#これらのTiDBクラスターをコンピューティングリソースに展開するソフトウェア群としてtiupが存在します。
このツール群に含まれるtiup playgroundはローカル環境でTiDBを手頃で展開できるようにするデモアプリです。
本番の挙動と異なる点がありますが、今回はこちらを使ってデモをしようと思います。
筆者が検証に使った環境は次のとおりです。
- MacBook Air(Apple M2)
- OS: macOS Ventura ver13.5
- メモリ: 16GB
2. tiupのインストール
#2024年8月現在、次のコマンドでtiupをインストールできます。
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
このとき、PATHにtiupを追加する作業も済ませておいてください。
3. データベースのセットアップ
#tiupがインストールされていることを確認したら、以下のコマンドを実行してクラスタを起動してください。
tiup playground v6.5.1 --tag demo --db 2 --pd 3 --kv 3 --tiflash 1
成功すればテストクラスタを起動できます。
> tiup playground v6.5.1 --tag demo --db 2 --pd 3 --kv 3 --tiflash 1
Start pd instance:v6.5.1
Start pd instance:v6.5.1
Start pd instance:v6.5.1
Start tikv instance:v6.5.1
Start tikv instance:v6.5.1
Start tikv instance:v6.5.1
Start tidb instance:v6.5.1
Start tidb instance:v6.5.1
Waiting for tidb instances ready
127.0.0.1:58012 ... Done
127.0.0.1:58014 ... Done
Start tiflash instance:v6.5.1
Waiting for tiflash instances ready
127.0.0.1:3930 ... Done
🎉 TiDB Playground Cluster is started, enjoy!
Connect TiDB: mysql --comments --host 127.0.0.1 --port 58014 -u root
Connect TiDB: mysql --comments --host 127.0.0.1 --port 58012 -u root
TiDB Dashboard: http://127.0.0.1:58007/dashboard
Grafana: http://127.0.0.1:59401
tiup playgroundを起動した端末とは別のものを用意して、出力されたポート(今回は58012 or 58014)にアクセスできればクラスタの起動は成功です。
> mysql -u root -P 58014 -h 127.0.0.1
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 415
Server version: 5.7.25-TiDB-v6.5.1 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
マシンの状態(使用port状況等)によってはクラスタの立ち上げが失敗します。
Start tidb instance:v6.5.1
Waiting for tidb instances ready
127.0.0.1:58731 ... Error
127.0.0.1:58733 ... Error
その場合には以下のコマンドでテストクラスタを完全に削除した後、もう一度立ち上げコマンドを実行してください。
tiup clean demo
4. テスト用テーブルの作成
#お手持ちのMySQLクライアントを用いてテーブルを作成していきましょう。
DDLは以下の通りです。
-- ユーザーの権限設定
CREATE USER IF NOT EXISTS 'newuser'@'%' IDENTIFIED BY 'newpassword';
GRANT ALL PRIVILEGES ON *.* TO 'newuser'@'%';
FLUSH PRIVILEGES;
-- データベースの作成
CREATE DATABASE IF NOT EXISTS test;
USE test;
-- usersテーブルが存在していればドロップ
DROP TABLE IF EXISTS users;
-- usersテーブルの作成
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
birthday DATE,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
上のSQLを適切な方法で実行してください[3]。
mysql -u root -P 58014 -h 127.0.0.1 < sample_ddl.sql
きちんとテストユーザでアクセスでき、データベースおよびテーブルが作成されていることが確認できたらOKです。
> mysql -u newuser -p -P 58014 -h 127.0.0.1
Enter password: ("newpassword"と入力)
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 419
Server version: 5.7.25-TiDB-v6.5.1 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> SHOW TABLES in test;
+----------------+
| Tables_in_test |
+----------------+
| users |
+----------------+
1 row in set (0.00 sec)
5. クライアントの準備と実行
#次にデータをテーブルに挿入するスクリプトを準備します。今回は自動てデータを投入してくれるPythonスクリプトを用意しました。
Pythonのバージョンは3.12.0であり、ライブラリのバージョンは以下の通りです。
# requirements.txt
mysql-connector==2.2.9
numpy==2.0.1
python-dotenv==1.0.1
その後、ライブラリをインストールします[4]。
次に環境変数を記述したファイル(ファイル名は.env)およびPythonスクリプト[5]を用意します(おなじ階層に保存してください)。
また、.envについてはTIDB_PORTとTIDB_PORT2をクラスタ立ち上げ時の出力で表示されているものに書き換える必要があります。
.envファイルは以下の通りです。
#.envという名前で保存する
TIDB_HOST="localhost"
TIDB_PORT=58014 # 環境によって適宜修正
TIDB_PORT2=58012 # 環境によって適宜修正
TIDB_PORT3=4002 # dummy
TIDB_USER="newuser"
TIDB_NAME="test"
TIDB_PASSWORD="newpassword"
TIDB_N_PORT= 2
Pythonコードは以下の通りです。
# tidb_test_client.py
from dotenv import load_dotenv
import uuid
import numpy as np
from mysql.connector import pooling, conversion, Error
import random
from datetime import datetime, timedelta
import time
import os
# .envファイルを読み込む
load_dotenv()
# .envファイルから環境変数を取得
HOST = os.environ.get("TIDB_HOST")
PORT = os.environ.get("TIDB_PORT")
PORT2 = os.environ.get("TIDB_PORT2")
PORT3 = os.environ.get("TIDB_PORT3")
USER = os.environ.get("TIDB_USER")
DB_NAME = os.environ.get("TIDB_NAME")
PASSWORD = os.environ.get("TIDB_PASSWORD")
N_PORT = int(os.environ.get("TIDB_N_PORT"))
NUM_RECORDS = 1_000
CHUNK_SIZE = 100
num_chunks = int(np.ceil(NUM_RECORDS / CHUNK_SIZE))
START_DATE = datetime(1980, 1, 1)
END_DATE = datetime(2024, 1, 1)
WAIT_TIME = 0.1
# ランダムな誕生日を生成
def get_random_birthday():
random_days = random.randint(0, (END_DATE - START_DATE).days)
birthday = START_DATE + timedelta(days=random_days)
return birthday
# SQLで挿入するデータを作成
# ユーザ名は乱数を使って生成し、誕生日はget_random_birthday関数を使って生成
values = [[str(uuid.uuid4()), get_random_birthday()] for _ in range(NUM_RECORDS)]
# portを引数としてデータベース接続設定を作成
def makeDBConfig (port):
return {
"host": HOST,
"port": port,
"user": USER,
"database": DB_NAME,
"password":PASSWORD
}
# N_PORTに応じて、接続先のポートのリストを作成
DB_PORTS = [PORT, PORT2, PORT3][:N_PORT]
# ポートごとにデータベース接続設定を作成
configs = [makeDBConfig(port) for port in DB_PORTS]
# Datetime64型をMySQLのDATETIME型に変換するためのクラス
class Datetime64Converter(conversion.MySQLConverter):
def _timestamp_to_mysql(self, value):
return value.strftime('%Y-%m-%d %H:%M:%S').encode('utf-8')
# コンフィグオブジェクトからデータベース接続を取得
def get_connection(config):
db_pool = pooling.MySQLConnectionPool(**config)
conn = db_pool.get_connection()
conn.set_converter_class(Datetime64Converter)
return conn
# データをチャンクに分割して、それぞれのチャンクをランダムに選択したポートに挿入
for i, chunk in enumerate(np.array_split(values, num_chunks)):
data = [tuple(x) for x in chunk]
while True:
# 0からlen(configs) - 1までの整数をランダムに選択
i_config = random.randint(0, len(configs) - 1)
# ランダムに選択したポートの設定を取得
config = configs[i_config]
print("----------------------------------")
print("ACCESSING PORT: ", config["port"])
try:
# データベースに接続
conn = get_connection(config)
# データベースにデータを挿入
cursor = conn.cursor()
sql = "INSERT INTO users (name, birthday) VALUES (%s, %s)"
cursor.executemany(sql, data)
# データベースにコミット
conn.commit()
# データベースに挿入されたレコードの数を取得して表示
cursor.execute("SELECT COUNT(*) FROM users")
count = cursor.fetchone()[0]
print(f"The number of records in the 'users' table: {count}")
# データベース接続を閉じる
conn.close()
time.sleep(WAIT_TIME)
# データベース接続が成功した場合、次のチャンクに進む
break
# エラーが発生した場合、次のポートに接続を試みる
except Error as err:
print(f"Something went wrong: {err}")
.envを適切に書き換えた上で、pythonスクリプトを実行してみてください。
次のような出力が確認できれば問題ありません。
> python tidb_test_client.py
----------------------------------
ACCESSING PORT: 58014
The number of records in the 'users' table: 100
----------------------------------
ACCESSING PORT: 58012
The number of records in the 'users' table: 200
----------------------------------
ACCESSING PORT: 58012
The number of records in the 'users' table: 300
(略)
ACCESSING PORT: 58014
The number of records in the 'users' table: 1000
大まかには以下の流れで処理を行います。
- 接続設定や挿入データの準備
- 実際のデータ挿入処理
また、2.実際のデータ挿入処理は以下のように処理しています。
- ランダムで接続先のTiDBノード(実際にはポート)を指定
- データの挿入や件数取得を行うクエリを実行
- 接続に失敗した場合には接続ポートを再選定
現在、疑似的なノードにローカルホスト上のポートが割り当てられてる状態です。TiDBに紐づけられているポートへのアクセス=TiDBノードへのアクセスと解釈してください。
6. ダッシュボードの確認
#ここでTiDBに搭載されているダッシュボード機能について紹介します。
tiup playgroundを立ち上げたコンソールの出力を確認すると、次のようにダッシュボードのurlが出力されています。
🎉 TiDB Playground Cluster is started, enjoy!
Connect TiDB: mysql --comments --host 127.0.0.1 --port 58014 -u root
Connect TiDB: mysql --comments --host 127.0.0.1 --port 58012 -u root
TiDB Dashboard: http://127.0.0.1:58007/dashboard ← Here!!!!!!!!!!!!!!!
Grafana: http://127.0.0.1:59401
このコンソールにあるリンクからダッシュボードアプリにアクセスできます。ユーザ名root, パスワードなしでログインできます。
TiDBダッシュボードではクラスタ上のメトリクスのほか、クエリの履歴といった情報を確認できます。
7. TiDBノードのスケーリング
#tiup playgroundではコマンド操作でノードのスケーリングができます。
再度、別のターミナルを立ち上げてください。
試しにストレージクラスタであるTiDBノードを1つスケールアウトさせてみましょう。
tiup playground scale-out --db 1
DBノードの作成に成功すると、次のような標準出力が出て、新しいDBクラスタのポート情報を確認できます。
> tiup playground scale-out --db 1
To connect new added TiDB: mysql --comments --host 127.0.0.1 --port 56139 -u root -p (no password)
tiup playgroundコマンドの実行結果を確認して、DBノードが増えていることが確認できれば問題ありません。
> tiup playground display
Pid Role Uptime
--- ---- ------
43104 pd 45m16.224283625s
43105 pd 45m16.21012975s
43106 pd 45m16.197087458s
43107 tikv 45m16.186158792s
43108 tikv 45m16.172459416s
43109 tikv 45m16.160307916s
43110 tidb 45m16.149157s
43111 tidb 45m16.139087333s
80169 tidb 1m50.744301584s ← Here!!!!!!!!!!!!!!!
43322 tiflash 45m1.901124666s
次に、.envファイルに戻ってTiDB_PORT3を新しいTiDBノードのポート番号に、TIDB_N_PORTを2→3に書き換えます。
#.env
TIDB_HOST="localhost"
TIDB_PORT=58014
TIDB_PORT2=58012
TIDB_PORT3=56139 #4002 ← Here!!!!!!!!!!!!!!!
TIDB_N_PORT=3 #2 ← Here!!!!!!!!!!!!!!!
TIDB_USER="newuser"
TIDB_NAME="test"
TIDB_PASSWORD="newpassword"
ここで再びpythonスクリプトを実行してみると、新しいポートにアクセスできていることが確認できます。
----------------------------------
ACCESSING PORT: 58012
The number of records in the 'users' table: 1100
----------------------------------
(略)
----------------------------------
ACCESSING PORT: 56139
The number of records in the 'users' table: 1700
----------------------------------
(略)
このように、クライアントとやり取りするノードを増やすことができました。
8. TiKVノードのスケーリング
#今度はTiKVクラスタの方も制御してみましょう。
同様に、ストレージクラスタであるTiKVを1つスケールアウトさせてみます。
tiup playground scale-out --kv 1
次に、KVクラスタをスケールインします。
tiup playground displayの出力結果を見ると、左にプロセスIDが確認できます。
Role tikvとなっているプロセスIDを指定して、以下のコマンドを実行してください。
tiup playground scale-in --pid 43107
tiup playground displayの出力結果を見ると、クラスター(のプロセス)が1つ消えていることがわかります。
> tiup playground display
Pid Role Uptime
--- ---- ------
43104 pd 1h3m11.156905s
43105 pd 1h3m11.142751291s
43106 pd 1h3m11.129707333s ↓ Pid 43107が消滅している
43108 tikv 1h3m11.105076833s
43109 tikv 1h3m11.092921208s
80382 tikv 11m14.4069426845s
43110 tidb 1h3m11.081761667s
43111 tidb 1h3m11.071691958s
80169 tidb 19m45.676906459s
43322 tiflash 1h2m56.833724875s
先ほどのスクリプトを実行しても、特に問題なくデータが挿入されます。
このように、ストレージのノードを1つスケールインしても、クライアント側からやり取りできることが確認できました。
ただし、TiKVの同期を取るアルゴリズム(Raft)の性質上、TiKVノードは2個以上用意してください。TiKVノードが1個でもクライアントとの通信やデータの永続化は可能です(tiup playgroundにおいて)。しかしながら、分散ストレージの意味がなくなるため、望ましい状態ではありません。
9. tiup playgroundの終了
#用事が済んだら、以下のお片付けコマンドを実行してください。
tiup clean demo
テストデータはストレージに永続化されているため、このコマンドを実行しないと余分なストレージが消費されてしまいます。
A. tiup playgroundのチートシート
#ここまで出てきたコマンドのチートシートです。なお、"tiup"でtiupコマンドを起動できることが前提です。
TiDBクラスタの起動
#tiup playground ${バージョン} --tag ${タグ名} --db ${DBの個数} --pd ${PDの個数} --kv ${KVの個数} --tiflash ${TiFlashの個数}
今回の例で実行したコマンドは以下の通りです。
tiup playground v6.5.1 --tag demo --db 2 --pd 3 --kv 3 --tiflash 1
クラスタ情報の表示
#tiup playground display
KVクラスタのスケールアウト
#tiup playground scale-out --kv 1
DBクラスタのスケールアウト
#tiup playground scale-out --db 1
クラスタのスケールイン
#tiup playground scale-in --pid ${ps_id}
※ プロセスIDはtiup playground displayで確認してください。
展開したTiDBクラスタの終了
#tiup clean ${起動時のタグ名}
TiDBの実行環境
#最後に、より実践的にクラスタを展開する方法が書かれた各種リファレンスのリンクを列挙します。
自分が所持するマシンやVMをクラスタに使う
#→ Deploy a TiDB Cluster Using TiUP
tiup playgroundではなく、tiup clusterというツールを使ってクラスタを展開できます。
テスト環境用のKubernetes実行環境で使う
#→ Get Started with TiDB on Kubernetes
TiDBはKubernetesでクラスタを構築できます。リンク先ではテスト用のkubernetesクラスタを構築できるkindを利用した場合の手順が紹介されています。
各種クラウドサービス上のKubernetes実行環境で使う
#→ Deploy TiDB on AWS EKS
→ Deploy TiDB on Google Cloud GKE
→ Deploy TiDB on Azure AKS
マネージドサービスを使う
#TiDB開発元であるPingCAP社はTiDBのマネージドサービス(DBaaS)であるTiDB Cloudを提供しています。
TiDB Cloudの中でも、自動でスケーリングされるフルマネージドな方式とクラスタの設定を自分で管理できる方式の2つが存在しています。
管理は意識せず、かつ必要な分だけ利用したい:
→ TiDB Serveless
クラスタ環境の構築や管理はしたくないが、クラスタの設定くらいはこちらで決めたい:
→ TiDB Dedicated
まとめ
#以上が分散データベースシステムTiDBの紹介でした。
より深く知りたいという方は公式のドキュメントを覗いてみてください。