OpenAI の Realtime API を使ってAIと音声会話するWebアプリを実装してみる
今までOpenAIのRealtime APIを使ってCLIベースの音声会話スクリプトを作成しました。
このスクリプトは音声変換ツールのSoX(Sound eXchange)のおかげで簡単に実装できましたが、やっぱりWebアプリも作ってみたいですね。
ここではVueフレームワークのNuxtを使用して、Webブラウザ上でRealtime APIと音声会話するアプリを作成します。
OpenAIの公式サンプルとしてReactベースのWebアプリがGitHubで公開されています。
本記事を執筆する上で、こちらのレポジトリも大いに参考にしています。
Webアプリの構成は以下のようになります。
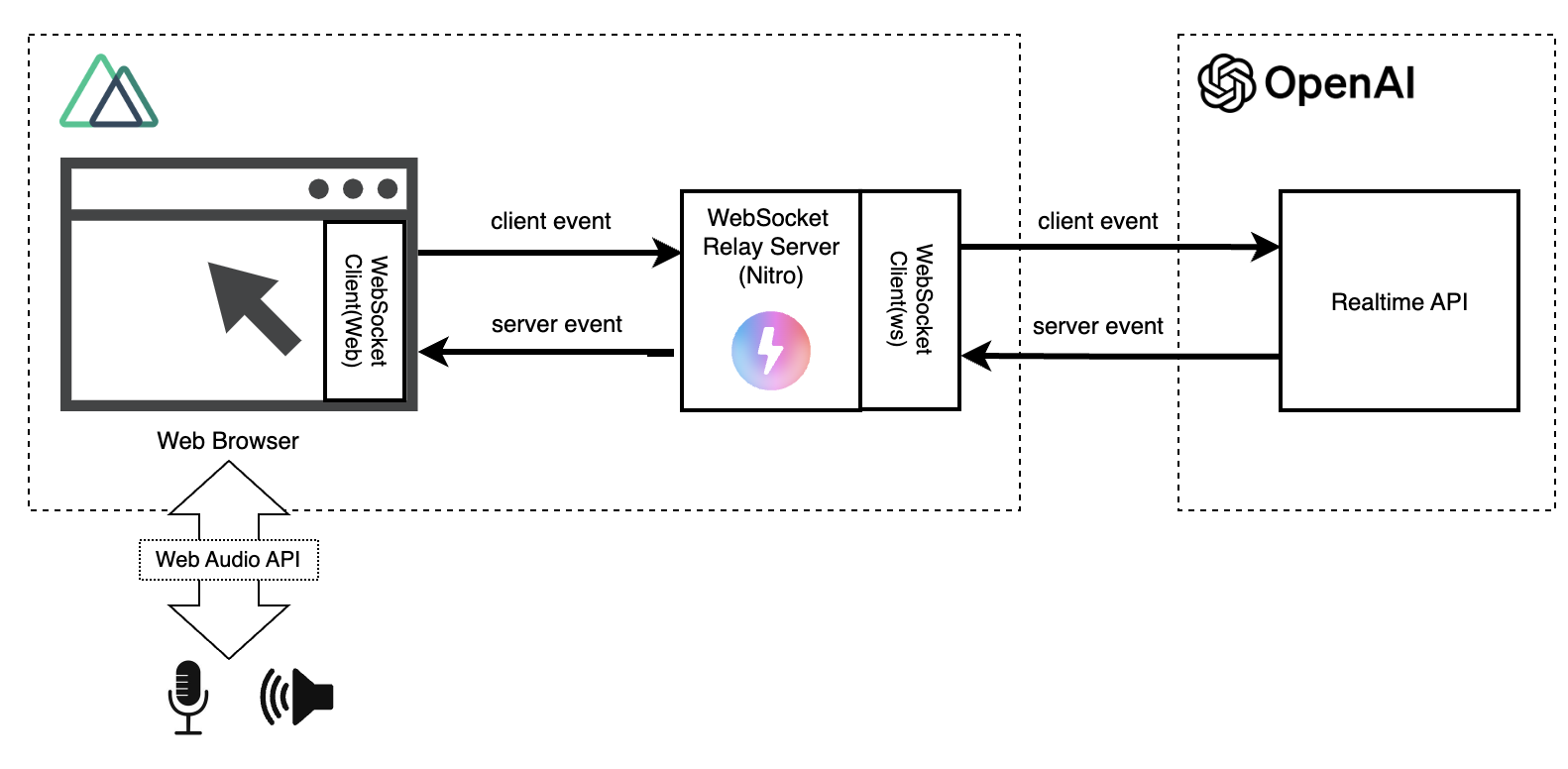
ブラウザ上から直接Realtime APIにアクセスする場合、利用者にOpenAIのAPIキーを晒すことになります。
これを避けるために、Nuxtが持つサーバー機能(Nitro)を使ってRealtime APIへのアクセスを仲介するようにしています。
以下はこのWebアプリを動かした動画です(ミュートを解除するとAIの音声が出ます。周囲の環境にご注意ください)。
この動画では(なぜか)私の入力音声は録音されませんでしたが、実際にはテキストメッセージや音声波形に表現されているように話してます。
本記事は重要な部分にフォーカスするため、全てのソースコードを掲載・説明しません。
ソースコードはGitHubで公開していますので、実際に試してみたい方は動かしてみていただければと思います(ただし、Realtime APIは結構高いので使い過ぎにご注意ください)。
本サンプルはRealtime APIを使ったアプリ開発を実験することを目的としており、シンプルさを重視した簡易実装です。
最低限の機能のみの実装で、スケーラビリティや耐障害性等は考慮していません。実運用で利用できるものではありません。
セットアップ
#概要のみ説明します。
まずNuxtのCLIからアプリケーションを作成します。
npx nuxi@latest init <nuxt-app-name>
cd <nuxt-app-name>
ここでは現時点で最新のv3.13.2のNuxtをインストールしました。
次に必要なライブラリをインストールします。
# WebSocketクライアント(Nitro)
npm install ws
# 開発系ライブラリ、Nuxtモジュール等(eslint, tailwindcss...)
npm install -D @types/ws eslint @nuxt/eslint @nuxtjs/tailwindcss
ブラウザ上からは、Web APIとしてブラウザに実装されているWebSocket APIを使いますが、サーバーサイドでのRealtime APIとのやりとりはwsを使います。
nuxt.config.tsは以下の通りです。
export default defineNuxtConfig({
compatibilityDate: '2024-04-03',
devtools: { enabled: true },
modules: ['@nuxtjs/tailwindcss', '@nuxt/eslint'],
// NitroのWebSocket対応
nitro: {
experimental: {
websocket: true,
},
},
eslint: {
config: {
stylistic: {
semi: true,
braceStyle: '1tbs',
},
},
},
});
ポイントはnitro.experimental.websocketの設定です。
Realtime APIを仲介するにはサーバー側もWebSocket通信が必要ですが、Nuxtがサーバーエンジンとして使用しているNitroのWebSocketは現状実験的扱いです。
上記の通り、利用する場合は明示的に有効化する必要があります。
アプリケーションの構造
#アプリケーションの主要コンポーネントは以下の通りです。
.
├── server
│ └── routes
│ └── ws.ts // Realtime APIのリクエストの中継サーバー
├── composables
│ ├── audio.ts // 音声の録音/再生
│ ├── audioVisualizer.ts // 音声波形の可視化
│ └── realtimeApi.ts // Realtime API通信
├── public
│ └── audio-processor.js // 録音した音声の変換処理(オーディオスレッド処理)
├── utils
│ └── index.ts // 共通関数をまとめたエントリーポイント(音声フォーマット変換のみのため省略)
├── app.vue // エントリーポイント
├── nuxt.config.ts
└── package.json
普通のNuxt SSRアプリケーションですが、serverディレクトリ配下にRealtime APIへの中継サーバーを用意しています。
ここからは、それぞれのコンポーネントの概要を説明します。
中継サーバー
#Nuxtでは、server/routesディレクトリ配下にソースコードを配置するだけでサーバーサイドのAPIを作成できます。
ここでは、これを使ってRealtime APIの中継サーバーを作成します。
ただし、ここでは通常のAPIではなくWebSocketサーバーとして実装することになります。
以下のように実装しました。
import { WebSocket } from 'ws';
// 接続ユーザー(peer)単位にRealtime APIのセッションを管理
const connections: { [id: string]: WebSocket } = {};
export default defineWebSocketHandler({
open(peer) {
if (!connections[peer.id]) {
// OpenAIのRealtime APIとの接続
const url = 'wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01';
connections[peer.id] = new WebSocket(url, {
headers: {
'Authorization': 'Bearer ' + process.env.OPENAI_API_KEY,
'OpenAI-Beta': 'realtime=v1',
},
});
}
const instructions = '明るく元気に話してください。仲の良い友人のように振る舞い、敬語は使わないでください。出力は日本語でしてください。';
connections[peer.id].on('open', () => {
// Realtime APIのセッション設定
connections[peer.id].send(JSON.stringify({
type: 'session.update',
session: {
voice: 'shimmer',
instructions: instructions,
input_audio_transcription: { model: 'whisper-1' },
turn_detection: { type: 'server_vad' },
},
}));
});
connections[peer.id].on('message', (message) => {
// Realtime APIのサーバーイベントはそのままクライアントに返す
peer.send(message.toString());
});
},
message(peer, message) {
// クライアントイベインとはそのままRealtime APIに中継する
connections[peer.id].send(message.text());
},
close(peer) {
connections[peer.id].close();
connections[peer.id] = undefined;
console.log('closed websocket');
},
error(peer, error) {
console.log('error', { error, id: peer.id });
},
});
WebSocketのサーバーAPI(Nitro)はdefineWebSocketHandlerを使って定義します。引数にはWebSocketの各種イベントフックを実装しています。
ここでの主な実装内容は以下です。
- Realtime APIとのコネクション接続・切断
- セッション設定(session.update)
- クライアントイベントをRealtime APIに中継
- サーバーイベントをクライアント(Webブラウザ)に中継
このように、Realtime APIとの接続以外は、クライアント(Webブラウザ)とRealtime APIからのイベントをそのまま中継するだけの機能しか持ち合わせていません。
これを単なる中継サーバーではなく、アプリケーションの用途に特化したAPIに改造すると、クライアント側の実装がスッキリした感じになりそうですね。
NuxtのサーバーエンジンのNitroでは、WebSocketサーバーの実装にcrosswsというクロスプラットフォーム対応のWebSocketライブラリを使用しています。
corsswsを使った実装の詳細は以下公式ドキュメントを参照してください。
ここでは使用してませんが、Pub/Subパターンも対応しており、複数ユーザーでの会話等も簡単に実装できます。
クライアント機能(Composables)
#今回部品として用意したComposableは3つです。
Realtime APIクライアント(realtimeApi.ts)
#Realtime APIクライアントと言っても、直接Realtime APIにアクセスする訳ではなく、中継サーバーを経由する形になります。
type Params = {
url: string;
logMessage: (string) => void;
onMessageCallback?: (message: MessageEvent) => void;
};
export const useRealtimeApi = ({ url, logMessage, onMessageCallback }: Params) => {
let ws: WebSocket | null = null;
const isConnected = ref(false);
function connect() {
if (isConnected.value) return;
ws = new WebSocket(url);
ws.onopen = () => {
logMessage('Connected to server🍻');
isConnected.value = true;
};
ws.onclose = () => {
logMessage('Disconnected👋');
isConnected.value = false;
};
ws.onerror = (error) => {
logMessage('Error occurred😭: ' + error.message);
};
ws.onmessage = (message: MessageEvent) => {
if (onMessageCallback) onMessageCallback(message); // Realtime APIのサーバーイベント
};
}
function disconnect() {
ws?.close();
}
function sendMessage(data: unknown) {
if (isConnected.value) {
ws?.send(JSON.stringify(data)); // Realtime APIのクライアントイベント
}
}
return {
connect,
disconnect,
sendMessage,
isConnected,
};
};
前述の通り、ここではブラウザに実装されているWebSocket APIを使って、中継サーバーとやりとりしています。
Realtime APIのサーバーイベントのハンドリングは、音声再生等のオーディオ関連の処理が必要になるため、ここで実装せずにパラメータで受け取ったコールバックを実行する形にしました。
オーディオ処理(audio.ts)
#マイクからの音声入力とRealtime APIからの音声出力をスピーカーから再生する機能を提供します。
全て掲載すると長くなるので、インターフェース部分を中心に抜粋します。
const BUFFER_SIZE = 8192;
const BUFFER_INTERVAL = 1000;
type Params = {
audioCanvas: Ref<HTMLCanvasElement>;
logMessage: (string) => void;
onFlushCallback: (buffer: ArrayBuffer) => void;
};
export function useAudio({ audioCanvas, logMessage, onFlushCallback }: Params) {
const isRecording = ref(false);
const isPlaying = ref(false);
// 省略
/**
* 音声録音開始関数
* 音声はバッファリングして一定サイズ超過または一定時間経過後にコールバック実行
*/
async function startRecording() {
isRecording.value = true;
try {
// マイクの準備(許可要求)
const mediaStream = await navigator.mediaDevices.getUserMedia({ audio: true });
audioContext = new (window.AudioContext || window.webkitAudioContext)({ sampleRate: 24000 });
// 省略(音声入力変換とコールバック処理実行)
} catch (e) {
// 省略
}
}
/**
* 音声録音停止関数
*/
function stopRecording() {
// 省略
}
/**
* 再生する音声をキューに格納 -> 順次再生
*/
function enqueueAudio(buffer: ArrayBuffer) {
audioQueue.push(arrayBufferToAudioData(buffer));
if (!isPlaying.value) {
playFromQueue();
}
}
return {
startRecording,
stopRecording,
enqueueAudio,
isPlaying,
isRecording,
};
}
ブラウザに標準実装されているWeb Audio APIを使って、音声の録音と再生をします。
注意点として、Web Audio APIは32bit-float音声フォーマットが採用されていますが、Realtime APIは現時点でサポートしていません。
このため、デフォルトフォーマットのPCM16に録音、再生それぞれで相互変換が必要になります[1]。
また、音声は再生速度より早くストリームレスポンスとして返ってきますので、キューイング処理を実装しないと音声が重なって出力されてしまう問題が発生しました。
Realtime APIとは直接関係のない部分ですが、ここが一番苦労しました😂
とはいえ、オーディオ処理は音声を使ったプログラミングではUIとも言える部分になるので、もっと精進せねばと思いました。
オーディオ可視化(audioVisualizer.ts)
#Canvas要素に音声信号を波形表示で描画する機能を提供します。
Web APIとしてブラウザで提供されているオーディオ分析ツールのAnalyserNodeを使って音声信号をリアルタイムで可視化します。
この機能は記事の本題でありませんのでソースコード掲載は省略します。
エントリーポイント(app.vue)
#最後はアプリケーションのエントリーポイントです。
今回は単一ページなので、ページコンポーネントをNuxtエントリーポイントのapp.vueに直接実装しました。
各種機能をComposableとして部品に切り出しましたので、ページコンポーネントはシンプルになりました。
UIレンダリングは本題から逸れるので、以下音声録音とRealtime API連携部分を抜粋して説明します。
音声録音
#主要な処理はオーディオ処理(audio.ts)のComposableで実装しています。
このページコンポーネントの責務は、録音した音声のフラッシュ[2]時の処理(コールバック関数)を実装することです。
// 再生音声フラッシュ時のコールバック
function handleAudioFlush(buffer: ArrayBuffer) {
// マイクからの音声入力をRealtime APIに送信
sendMessage({ type: 'input_audio_buffer.append', audio: arrayBufferToBase64(buffer) });
}
const { startRecording, stopRecording, enqueueAudio, isRecording } = useAudio({
audioCanvas, // 波形表示用のCanvs
logMessage, // ログ追加コールバック
onFlushCallback: handleAudioFlush, // 音声フラッシュ時のコールバック
});
ここではバッファリングした音声データをBase64エンコードしてinput_audio_buffer.appendイベントをRealtime APIに送信します。
Realtime API
#Realtime APIまわりのWebSocketクライアントの実装もComposableとして部品に切り出してますので、ここではサーバーイベント発生時のイベントハンドラを実装して渡してあげるだけです。
// RealtimeAPIのサーバーイベントハンドラ
function handleWebSocketMessage(message: MessageEvent) {
const event = JSON.parse(message.data);
logEvent(event.type);
switch (event.type) {
case 'response.audio.delta': {
enqueueAudio(base64ToArrayBuffer(event.delta));
break;
}
case 'response.audio_transcript.done':
// レスポンスより早くイベントが発火することがあるのでロギングを遅延させる
setTimeout(() => logMessage(`🤖: ${event.transcript}`), 100);
break;
case 'conversation.item.input_audio_transcription.completed':
logMessage(`😄: ${event.transcript}`);
break;
case 'error':
logEvent(event.error);
if (isRecording.value) stopRecording();
// Realtime APIは15分経過するとセッションタイムアウトする
if (event.code === 'session_expired') disconnect();
break;
default:
break;
}
}
// Realtime API
const { connect, isConnected, disconnect, sendMessage } = useRealtimeApi({
url: 'ws://localhost:3000/ws',
logMessage,
onMessageCallback: handleWebSocketMessage,
});
ここでのコールバック関数のメイン処理は以下2つです(エラー処理は省きます)。
音声データの再生
Realtime APIの音声出力はresponse.audio.deltaイベントのペイロードに設定されます。音声データは一度に全てではなくストリーム形式で段階的に差分(delta)が格納されてきます。
これをオーディオ処理のキューに溜めます(enqueueAudio)。このキューはスピーカーから順次再生されます。
テキストメッセージ描画
Realtime APIでは音声データだけでなく、入力音声、出力音声のテキストメッセージも出力できます。
ここでは、このイベントをフックしてリアクティブ変数に格納しています。結果的にこれはチャット風にリアルタイムで表示されます。
まとめ
#以上概要レベルになりますが、Realtime APIを使ったWebアプリ開発を試してみたポイントを説明しました。
特に音声系の処理はハマりポイントがたくさんあって苦労しました。
とはいえ、Webアプリであれば多人数での利用が容易で、多くの使いどころが考えられます。
時間を見つけてスケーラビリティといった部分も改善していければと思います。
OpenAI公式のサンプルでは、変換処理は入力・出力ともにAudioWorkletを使ってオーディオスレッドでオフロード実行していますが、本サンプルは入力のみで使用しています。実運用レベルにする場合は公式サンプルのように出力側もオーディオスレッドで実行するのが望ましいと思います。 ↩︎
デフォルト状態では256バイトずつ音声データが処理され、高頻度で音声が送信されてしまいます。オーディオ処理のComposableでは音声データをバッファリングして、8192バイトまたは1秒おきにフラッシュするようにしています。 ↩︎