Kubernetes ネイティブなワークフローエンジン Argo Workflows
Argo Workflows は Kubernetes で動作するワークフローエンジンです。コンテナイメージを利用してジョブを記述でき、Kubernetes 上でそのまま実行できます。ワークフローというと、業務プロセスを実行する BPM エンジンを連想される方も多いと思いますが、Argo Workflows は GitHub Actions などと同様、CI/CD などのワークフロー(ジョブ)を記述・実行できるエンジンです。Kubernetes で動作する機械学習の OSS スイートである Kubeflow でも機械学習パイプラインを実行するためのエンジンとして採用されています。
最近は Kubernetes をターゲットに開発・運用されるシステムが増えてきました。CI/CD ワークフローを Kubernetes で実行できるメリットは色々と挙げられます。
- マシンリソースの調整がやりやすい
- CPU やメモリを多く必要とするワークフローでも Kubernetes の機能で簡単にマシンリソースを割り当てることができます。
- 本番環境と同じ構成でソフトウェアを実行できる
- 実行環境が本番環境と同等であるため、CI で早期に環境起因の不具合を検出できます。ワーカーノード構成、ストレージやネットワーク回りなど、開発環境と本番環境で差異が大きいと、本番で思わぬ不具合が出て対応が遅くなることもあります。CI を本番同様の構成で実行できればこのような状況を防止しやすくなります。
- 外部のサービスを利用しなくてもワークフローが実現できる
- GitHub Actions や AWS CodePipeline のような外部の CI/CD サービスを利用しなくても、開発用の Kubernetes クラスター上にパイプラインが構築できます。
- ストレージや各種パッケージレジストリも AWS S3 や ECR などを利用しなくても 各種 OSS の Pod をデプロイして利用できます。
- ソースコードやデータの秘匿がやりやすい
- プライベートな Kubernetes クラスターに閉じていれば、機微なデータもクラウドを利用するよりは扱いやすくなります。
Argo Workflows のデプロイについては、公式のマニフェストかコミュニティベースの Helm Chart を利用可能です。
- 公式マニフェスト : argo-workflows/manifests · argoproj/argo-workflows
- Helm Chart : argo-helm/charts/argo-workflows argoproj/argo-helm
Argo Workflows でのワークフロー作成については公式の example がそのままチュートリアルになっているため、参照しながら雰囲気を掴んでみましょう。
argo-workflows/examples - argoproj/argo-workflows
複数ステップからなるワークフロー定義の例です(Steps サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: steps-
spec:
entrypoint: hello-hello-hello
# This spec contains two templates: hello-hello-hello and whalesay
templates:
- name: hello-hello-hello
# Instead of just running a container
# This template has a sequence of steps
steps:
- - name: hello1 # hello1 is run before the following steps
template: whalesay
arguments:
parameters:
- name: message
value: "hello1"
- - name: hello2a # double dash => run after previous step
template: whalesay
arguments:
parameters:
- name: message
value: "hello2a"
- name: hello2b # single dash => run in parallel with previous step
template: whalesay
arguments:
parameters:
- name: message
value: "hello2b"
# This is the same template as from the previous example
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
ワークフロー定義は、Kubernetes の manifest になっています。kind で CRD である Workflow を指定します。spec で entrypoint となる template を呼び出します。template はネストでき、再利用ができます。template の記述自体は、わかりやすいシンタックスの YAML であり、GitHub Actions などのモダンなワークフローの利用経験があれば、さほど違和感なく読み書きできると思います。
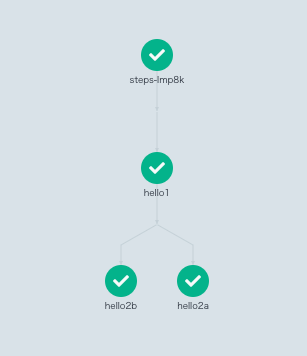
トップレベルの template は hello-hello-hello であり、これが Workflow manifest の spec/entorypoint に書かれているので、steps が実行されます。
Steps サンプルでは、hello1 が最初に実行され、hello1 に続いて hello2a が実行されます。name 属性についている double dash - - は、先頭の要素の場合、続く step より先に実行されます。2個目以降の要素の場合は、先行する step に続いて実行されます。single dash - の場合は順序制御がないので、hello2b は hello2a と並列に実行されます。
hello-hello-hello の各 step からは、whalesay という template が再利用されて呼び出されています。これは、whalesay のコンテナイメージを使って、command に各 step の agments/parameters で指定された引数を渡して実行しています。
Argo workflow の Web UI で実行結果を見るとこのようになります。
Steps サンプルの double dash による順序制御が直感的でないと思う人には、オプションとして DAG 記法も提供されており、おなじみの書き方も可能です(DAG サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-diamond-
spec:
entrypoint: diamond
templates:
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: A}]
- name: B
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: B}]
- name: C
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: C}]
- name: D
dependencies: [B, C]
template: echo
arguments:
parameters: [{name: message, value: D}]
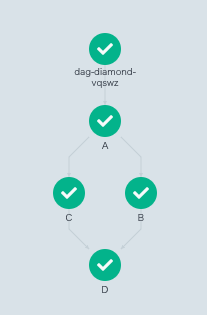
dag 宣言の後 tasks の dependencies で先行 task を指定できます。C と B は先行 task に A を 指定しているので並行実行されます(フォーク)。D は先行 task に B と C を指定しているので、両方の完了を待って実行されます(ジョイン)。
実行結果はこのようになります。
Argo workflows の特徴的な機能として here script があり、各プログラミング言語のソースコードを直接書けます(Scripts & Results サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: scripts-bash-
spec:
entrypoint: bash-script-example
templates:
- name: bash-script-example
steps:
- - name: generate
template: gen-random-int-bash
- - name: print
template: print-message
arguments:
parameters:
- name: message
value: "{{steps.generate.outputs.result}}" # The result of the here-script
- name: gen-random-int-bash
script:
image: debian:9.4
command: [bash]
source: | # Contents of the here-script
cat /dev/urandom | od -N2 -An -i | awk -v f=1 -v r=100 '{printf "%i\n", f + r * $1 / 65536}'
- name: gen-random-int-python
script:
image: python:alpine3.6
command: [python]
source: |
import random
i = random.randint(1, 100)
print(i)
- name: gen-random-int-javascript
script:
image: node:9.1-alpine
command: [node]
source: |
var rand = Math.floor(Math.random() * 100);
console.log(rand);
- name: print-message
inputs:
parameters:
- name: message
container:
image: alpine:latest
command: [sh, -c]
args: ["echo result was: {{inputs.parameters.message}}"]
シェルスクリプト以外の言語で処理をかけるので有効な局面もあるでしょう。
CI では、色々な環境の組み合わせでテストを流したいことがあります。OS、プログラミング言語、ライブラリとそれらの各バージョンなど多くの組み合わせで同じテストを流す。これは Matrix build などとも呼ばれています。Argo workflows には Matrix build の機能はありませんが、オブジェクトのリストを iterate する機能を使って近いことができます(Loops サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: loops-maps-
spec:
entrypoint: loop-map-example
templates:
- name: loop-map-example
steps:
- - name: test-linux
template: cat-os-release
arguments:
parameters:
- name: image
value: "{{item.image}}"
- name: tag
value: "{{item.tag}}"
withItems:
- { image: 'debian', tag: '9.1' } #item set 1
- { image: 'debian', tag: '8.9' } #item set 2
- { image: 'alpine', tag: '3.6' } #item set 3
- { image: 'ubuntu', tag: '17.10' } #item set 4
- name: cat-os-release
inputs:
parameters:
- name: image
- name: tag
container:
image: "{{inputs.parameters.image}}:{{inputs.parameters.tag}}"
command: [cat]
args: [/etc/os-release]
withItems で指定したオブジェクトのリストを iterate して cat-os-release template を実行します。
以下 Kubernetes の特性を活かした Argo Workflows の特徴的な機能を見ていきましょう。
コンテナを Daemon として起動する例です(Daemon Containers サンプルから)
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: daemon-step-
spec:
entrypoint: daemon-example
templates:
- name: daemon-example
steps:
- - name: influx
template: influxdb # start an influxdb as a daemon (see the influxdb template spec below)
- - name: init-database # initialize influxdb
template: influxdb-client
arguments:
parameters:
- name: cmd
value: curl -XPOST 'http://{{steps.influx.ip}}:8086/query' --data-urlencode "q=CREATE DATABASE mydb"
- - name: producer-1 # add entries to influxdb
template: influxdb-client
arguments:
parameters:
- name: cmd
value: for i in $(seq 1 20); do curl -XPOST 'http://{{steps.influx.ip}}:8086/write?db=mydb' -d "cpu,host=server01,region=uswest load=$i" ; sleep .5 ; done
- name: producer-2 # add entries to influxdb
template: influxdb-client
arguments:
parameters:
- name: cmd
value: for i in $(seq 1 20); do curl -XPOST 'http://{{steps.influx.ip}}:8086/write?db=mydb' -d "cpu,host=server02,region=uswest load=$((RANDOM % 100))" ; sleep .5 ; done
- name: producer-3 # add entries to influxdb
template: influxdb-client
arguments:
parameters:
- name: cmd
value: curl -XPOST 'http://{{steps.influx.ip}}:8086/write?db=mydb' -d 'cpu,host=server03,region=useast load=15.4'
- - name: consumer # consume intries from influxdb
template: influxdb-client
arguments:
parameters:
- name: cmd
value: curl --silent -G http://{{steps.influx.ip}}:8086/query?pretty=true --data-urlencode "db=mydb" --data-urlencode "q=SELECT * FROM cpu"
- name: influxdb
daemon: true # start influxdb as a daemon
retryStrategy:
limit: 10 # retry container if it fails
container:
image: influxdb:1.2
readinessProbe: # wait for readinessProbe to succeed
httpGet:
path: /ping
port: 8086
- name: influxdb-client
inputs:
parameters:
- name: cmd
container:
image: appropriate/curl:latest
command: ["/bin/sh", "-c"]
args: ["{{inputs.parameters.cmd}}"]
resources:
requests:
memory: 32Mi
cpu: 100m
少し長いですが、InfluxDB を最初に実行される influx step で起動しています。ここで指定されている influxdb template では daemon: true を指定することで、実行される template のスコープで daemon コンテナとして利用できます。後続の step で InfluxDB を初期化し複数の producer が並列でデータを投入します。最後に consumer が投入されたデータを読み出します。このように実行される template のスコープで常に利用できるコンテナを起動できるので、
- 開発中の Web アプリケーションを daemon として起動しテストする
- コンテナレジストリや NPM パッケージレジストリを daemon として起動し、ワークフロー実行中に成果物を push / pull する
などの用途が考えられます。
メインのコンテナと同一 Pod で起動するサイドカーコンテナを指定することもできます(Sidecars サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: sidecar-nginx-
spec:
entrypoint: sidecar-nginx-example
templates:
- name: sidecar-nginx-example
container:
image: appropriate/curl
command: [sh, -c]
# Try to read from nginx web server until it comes up
args: ["until `curl -G 'http://127.0.0.1/' >& /tmp/out`; do echo sleep && sleep 1; done && cat /tmp/out"]
# Create a simple nginx web server
sidecars:
- name: nginx
image: nginx:1.13
メインとなる curl のコンテナからサイドカーの nginx を利用しています。同一 Pod なので 12.0.0.1 を指定しています。
サイドカーを応用すると Docker in Docker な処理も実現できます(Docker-in-Docker Using Sidecars サンプルから)。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: sidecar-dind-
spec:
entrypoint: dind-sidecar-example
templates:
- name: dind-sidecar-example
container:
image: docker:19.03.13
command: [sh, -c]
args: ["until docker ps; do sleep 3; done; docker run --rm debian:latest cat /etc/os-release"]
env:
- name: DOCKER_HOST # the docker daemon can be access on the standard port on localhost
value: 127.0.0.1
sidecars:
- name: dind
image: docker:19.03.13-dind # Docker already provides an image for running a Docker daemon
env:
- name: DOCKER_TLS_CERTDIR # Docker TLS env config
value: ""
securityContext:
privileged: true # the Docker daemon can only run in a privileged container
# mirrorVolumeMounts will mount the same volumes specified in the main container
# to the sidecar (including artifacts), at the same mountPaths. This enables
# dind daemon to (partially) see the same filesystem as the main container in
# order to use features such as docker volume binding.
mirrorVolumeMounts: true
Docker イメージを使って debian のイメージを docker run しています。通常は Docker daemon が起動していないとダメなのですが、サイドカーとして docker の dind イメージを起動していることで実現しています。
失敗した step のリトライでも Kubernetes の機能が活かせます(Retrying Failed or Errored Steps サンプルから)。
# This example demonstrates the use of retry back offs
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: retry-backoff-
spec:
entrypoint: retry-backoff
templates:
- name: retry-backoff
retryStrategy:
limit: 10
retryPolicy: "Always"
backoff:
duration: "1" # Must be a string. Default unit is seconds. Could also be a Duration, e.g.: "2m", "6h", "1d"
factor: 2
maxDuration: "1m" # Must be a string. Default unit is seconds. Could also be a Duration, e.g.: "2m", "6h", "1d"
affinity:
nodeAntiAffinity: {}
container:
image: python:alpine3.6
command: ["python", -c]
# fail with a 66% probability
args: ["import random; import sys; exit_code = random.choice([0, 1, 1]); sys.exit(exit_code)"]
この例では、66%の確率で失敗する step を定義し、retryStrategy により10回までのリトライ、待ち時間を指数関数的に増やす、などを指定しています。affinity の指定では nodeAntiAffinity を指定しており、Step で実行する Pod が同じワーカーノードにスケジューリングされないようなポリシーを指定しています。これによりワーカーノードの異常など環境要因での失敗を繰り返す可能性を軽減できます。
以上のように、Argo workflows は Kunbernetes で実行できることにとどまらず、kubernetes の特徴を活かした機能を豊富に提供しています。
現状 Git リポジトリへの push をトリガーにして実行する機能は実装されていません(近い将来対応する計画はあるそうです)。Argo Events と組み合わせれば Git への push をトリガーとして Argo Workflow を起動するよう構成することも可能です。
Argo Events - The Event-Based Dependency Manager for Kubernetes