メトリクス収集・可視化 - Prometheus / Grafana
今回のテーマはモニタリングです。
アプリケーションの運用が開始されると、ピーク時間帯や各種イベントに応じてシステム負荷は大きく変動します。
特に、マイクロサービスアーキテクチャでは、臨機応変なスケーラビリティや、無駄なのないリソース効率性とそれに応じたコスト最適化が求められます。
このような状況下では、各サービスレベルできめ細かい情報を収集・可視化することがより重要となります。
モニタリング編では、以下の項目に焦点を当て、それぞれハンズオン形式で実施してみたいと思います。
- メトリクス:リソース使用率等の各種メトリクス収集と可視化
- ロギング:各サービスのログを一元管理・検索
- トレーシング:サービス間のリクエスト/イベントのパフォーマンス測定
まずはメトリクスです。
メトリクスは、Kubernetesだと、Prometheusを思い浮かべる方が多いかと思います。
Prometheusは、分散アーキテクチャに対応するモニタリングツールとして人気を博し、コンテナ型システムでは定番といえるツールです。
ただ、Prometheus以外にもDatadog、New Relic、クラウドプロバイダーのマネージドサービス等、モニタリングツールは数多く存在します。各ツールは独自プロトコルを採用していることが多く、昨今はその互換性について意識されるようになってきました。
ここで登場するのがOpenTelemetryです。
OpenTelemetryは、メトリクスやトレーシングで標準化を目指していたOpenTracingとOpenCensusを統合する形で誕生した総合的なメトリクスの仕様で、2021/5にv1.0がリリースされました。
現在OpenTelemetryは、CNCF(Cloud Native Computing Foundation)のIncubatingプロジェクト[1]としてホスティングされており、各SaaS/クラウドベンダーを巻き込んで、各種実装やディストリビューションが開発されています。
ここでは、成熟した域に達しているPrometheusと、OpenTelemetryを利用したメトリクス収集と可視化について、2回に分けて実施していきます。
なお、OpenTelemetryについては、現状アクティブに開発が進められている点もあり、実際に採用する際は最新の状況を確認することをお勧めします。
事前準備
#まずはAWS EKS環境を準備してください。ただし、Prometheus自体はAWSに依存するものではありませんので、ローカル環境や他のクラウド環境でも同様のことは可能です。
また、アプリケーションは以下で使用したものを使います。
- クラスタ環境デプロイ - コンテナレジストリ(ECR)
- クラスタ環境デプロイ - EKSクラスタ(AWS環境準備)
- クラスタ環境デプロイ - EKSクラスタ(Kustomize導入)
- クラスタ環境デプロイ - EKSクラスタ(デプロイ)
Prometheus、Grafanaのインストール
#では、Prometheus/Grafanaをセットアップしましょう。
Prometheus単体でも可視化ツールは付属していますが、ここではよりリッチなUI/UXを提供するGrafanaも合わせてインストールします。
両ツールをKubernetes Operatorとして管理するkube-prometheus-stackがPrometheusコミュニティで提供されていますので、今回はそちらを利用します[2]。
まず、Helmチャートのリポジトリを追加します。
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kube-prometheus-stackを以下のコマンドでインストールします。現時点で最新の33.2.0のHelmチャートを利用するように指定しました。
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--install --version 33.2.0 \
--namespace prometheus --create-namespace \
--set grafana.ingress.enabled=true \
--set grafana.ingress.ingressClassName=nginx \
--wait
今回はインストール時に、Grafana向けにIngressをセットアップしました。
インストールしたものの状態を確認してみましょう。
kubectl get pod -n prometheus
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 0 34s
kube-prometheus-stack-grafana-78f99bc987-r6nvc 3/3 Running 0 43s
kube-prometheus-stack-kube-state-metrics-d699cc95f-dlbwf 1/1 Running 0 43s
kube-prometheus-stack-operator-6b5bf9c455-rw9rl 1/1 Running 0 43s
kube-prometheus-stack-prometheus-node-exporter-qhrng 1/1 Running 0 43s
kube-prometheus-stack-prometheus-node-exporter-sg6q7 1/1 Running 0 43s
prometheus-kube-prometheus-stack-prometheus-0 1/2 Running 0 34s
prometheusNamespaceにPrometheus関連の各コンポーネントと、可視化ツールのGrafanaが実行されています。
Kubernetesメトリクス収集・可視化
#kube-prometheus-stackでは、デフォルトでデータソース(=Prometheus)の設定に加えて、Kubernetesのコンテナ関連のメトリクス収集やGrafanaのダッシュボードがセットアップされています。
したがって、インストールした時点で既に各種メトリクス収集が始まり、Grafanaダッシュボードをメトリクスを確認できます。
まず、Grafanaのエンドポイントを確認しましょう。
kubectl get ingress kube-prometheus-stack-grafana -n prometheus \
-o jsonpath='{.status.loadBalancer.ingress[0].hostname}'; echo
今回はGrafanaのIngressのカスタムドメインやHTTPS化はしていませんので、ブラウザから出力されたURL(AWS ELBアドレス)にアクセスしましょう[3]。
ログインページが表示されたら、ユーザーIDとパスワードを入力します。
今回は初期状態のデフォルトのユーザーIDadminを利用します。パスワードは以下より取得できます[4]。
kubectl get secret kube-prometheus-stack-grafana -n prometheus \
-o jsonpath='{.data.admin-password}' | base64 --decode; echo
Prometheus/Grafanaともに、ゼロからメトリクス収集やダッシュボード設定をするのはそれなりに学習が必要です。
しかし、前述の通り、kube-prometheus-stackにはデフォルトでKubernetes関連のメトリクス収集・可視化の設定が施されています。
ここでは、デフォルトで収集されているKubernetes関連のメトリクスの一部を確認してみましょう。
ログイン後にサイドバーの虫眼鏡アイコンをクリックします。
ダッシュボード検索ページのGeneralフォルダ内に、デフォルトでセットアップ済みのダッシュボードが確認できます。

任意のダッシュボードを選択して、ダッシュボードを表示してみましょう。
例えば、Kubernetes / Compute Resource / Clusterを選択すると、以下のようなダッシュボードが表示されます。
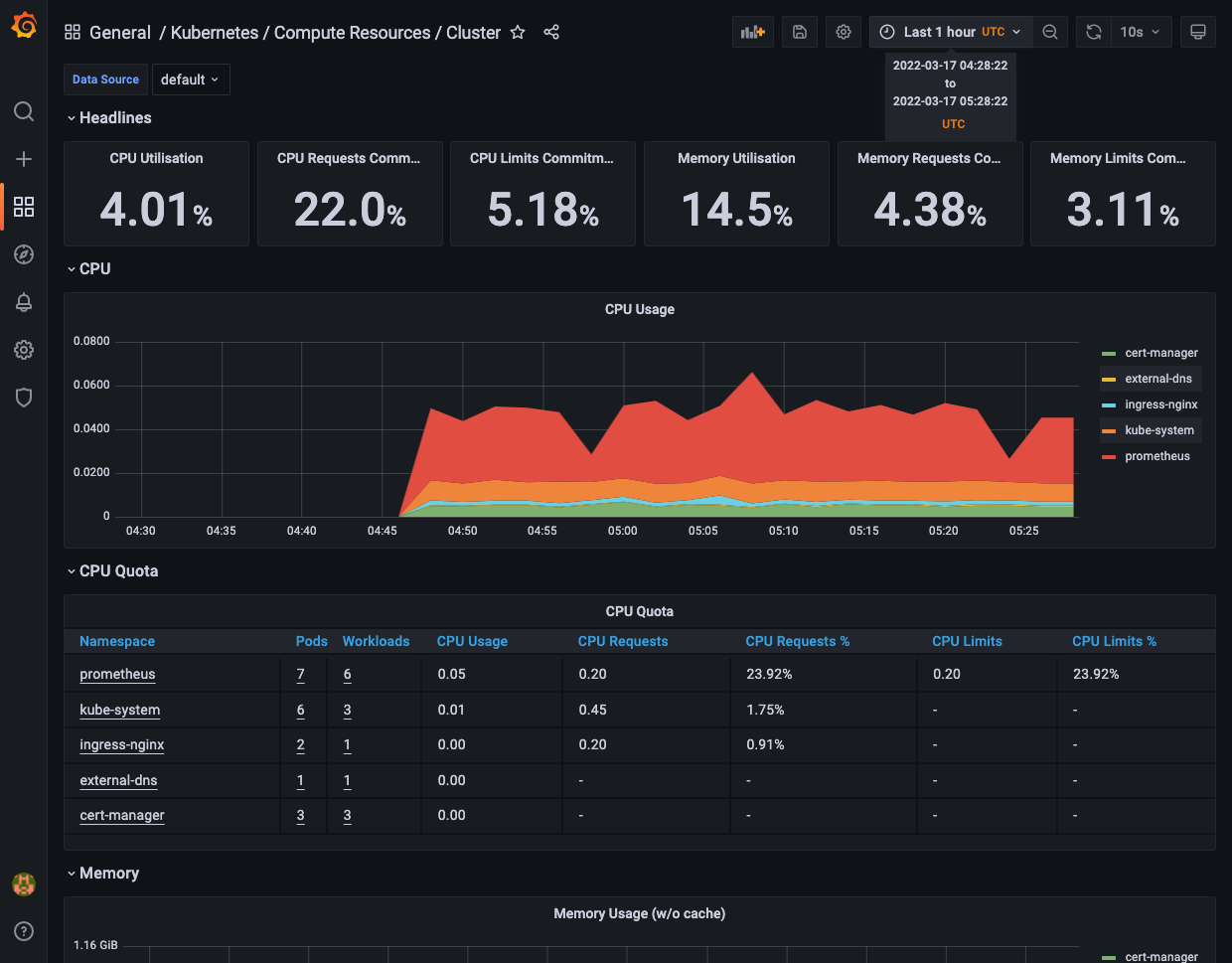
クラスタ全体やPodレベルのリソース使用率が、一目瞭然で分かります。
Prometheusクライアントのセットアップ
#今までいわゆるインフラレベルのメトリクスをダッシュボード化したものを見てきましたが、アプリケーションレベルのメトリクスも収集・可視化してみましょう。
今回メトリクス収集の対象として、Node.js+Expressで実装しているREST APIサービスであるtask-serviceを対象にアプリケーションメトリクスを収集します。
Node.jsの場合は、Prometheusクライアントとしてprom-clientを利用すると、アプリケーションのカスタムメトリクスをPrometheusに送ることができます。
これ単体で実装することもできますが、今回は自動でNode.jsのメトリクスを生成し、エンドポイントを公開するprometheus-api-metricsを使用します。
app/apis/task-service配下で、prometheus-api-metricsをインストールします。
npm install prometheus-api-metrics
後は、エントリーポイントのindex.tsでセットアップ用のコードを追加するだけです。
関連部分のみ抜粋します。
import apiMetrics from 'prometheus-api-metrics';
const app = express();
app.use(express.json());
// Express appに登録
app.use(apiMetrics())
これだけで、Prometheus向けのメトリクス収集エンドポイントが/metricsで公開されます[5]。
実際にこのエンドポイントにアクセスしてみると、以下のようなPrometheusフォーマットでNode.jsのメトリクスが取得できます。
# HELP process_cpu_user_seconds_total Total user CPU time spent in seconds.
# TYPE process_cpu_user_seconds_total counter
process_cpu_user_seconds_total 0.575932
# HELP process_cpu_system_seconds_total Total system CPU time spent in seconds.
# TYPE process_cpu_system_seconds_total counter
process_cpu_system_seconds_total 0.146791
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 0.722723
# 中略
# HELP http_request_duration_seconds Duration of HTTP requests in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.001",method="GET",route="/health/readiness",code="200"} 0
http_request_duration_seconds_bucket{le="0.005",method="GET",route="/health/readiness",code="200"} 0
http_request_duration_seconds_bucket{le="0.015",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.05",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.1",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.2",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.3",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.4",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="0.5",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_bucket{le="+Inf",method="GET",route="/health/readiness",code="200"} 1
http_request_duration_seconds_sum{method="GET",route="/health/readiness",code="200"} 0.009539549
http_request_duration_seconds_count{method="GET",route="/health/readiness",code="200"} 1
# 以下省略
CPU時間等の基本的な情報からレスポンスタイムまで、様々なアプリケーションメトリクスが取得できることが分かります。
メトリクスのフォーマットについては、Prometheusの公式ドキュメントを参照してください。
これでコンテナイメージをビルドし、コンテナレジストリにプッシュし、kubectlでアプリケーションをデプロイします。
# PROJECT_ROOTにはリポジトリルートを設定してください
cd ${PROJECT_ROOT}/app/apis/task-service
docker build -t <aws-account-id>.dkr.ecr.<aws-region>.amazonaws.com/mamezou-tech/task-service:1.0.0 .
docker push <aws-account-id>.dkr.ecr.<aws-region>.amazonaws.com/mamezou-tech/task-service:1.0.0
# デプロイ
kubectl apply -f ${PROJECT_ROOT}/k8s/v3/overlays/prod
# アプリケーション状態確認
kubectl get pod -n prod
既にアプリケーションをデプロイ済みの場合は、以下のいずれかの方法でアプリケーションを更新してください。
- 別タグ(
2.0.0等)でイメージをビルド/プッシュ後に、kustomization.yamlのimagesのタグを更新して再デプロイ。- スケジュールされたノードに旧バージョンのイメージがキャッシュ済みの場合は、キャッシュが使用されてアプリケーションは更新されません。
- 同一タグのイメージをビルド/プッシュ後に、
task-serviceDeploymentのimagePullPolicyをAlwaysに変更して、Podを再起動(kubectl rollout restart deploy prod-task-service)。
prometheus-api-metricsは、デフォルトでpackage.jsonからバージョン情報をメトリクスとして取得していますので、イメージ内にpackage.jsonを含める必要があります。
ここでは、task-serviceのDockerfileに以下を追加しました。
COPY /src/package.json ./
アプリケーションのセットアップはこれで完了です。
アプリケーションメトリクス収集・可視化
#Prometheusがこのメトリクスを収集するためには、Prometheus OperatorのカスタムリソースServiceMonitorを作成する必要があります。
このマニフェストファイルを作成しましょう(ここではservice-monitor.yamlとします)。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: task-service-monitor
namespace: prod
labels:
release: kube-prometheus-stack
spec:
endpoints:
- path: /metrics
targetPort: http
interval: 30s
selector:
matchLabels:
app: task-service
注意点としてはlabelsです。デフォルトではPrometheus Operatorはこのラベルがつけられたものをメトリクス収集対象として認識しますので、これがないとメトリクスは収集されません。
それ以外はendpointsでアプリケーション側のメトリクス収集のエンドポイントを指定し、selectorで収集対象のServiceオブジェクトのラベルを指定しています。
これでPrometheusはService経由で/metricsのエンドポイントから、30秒間隔でメトリクスを収集するようになります。
こちらを反映します。
kubectl apply -f service-monitor.yaml
このリソースが反映されるとPrometheus Operatorは実際のPrometheusの設定ファイルを更新します。どのように更新されたか見てみましょう。
PROM_POD=$(kubectl get -n prometheus pod -l app.kubernetes.io/name=prometheus -o jsonpath='{.items[0].metadata.name}')
kubectl exec -n prometheus -it $PROM_POD -c prometheus -- cat /etc/prometheus/config_out/prometheus.env.yaml
以下関連部分を抜粋します。
scrape_configs:
- job_name: serviceMonitor/prod/task-service-monitor/0
honor_labels: false
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- prod
scrape_interval: 30s
metrics_path: /metrics
relabel_configs:
- source_labels:
- job
target_label: __tmp_prometheus_job_name
- action: keep
source_labels:
- __meta_kubernetes_service_label_app
- __meta_kubernetes_service_labelpresent_app
regex: (task-service);true
# 以下省略
Service Monitorの設定内容が、Prometheusの設定ファイルとして反映されていることが分かります。
設定ファイルの内容詳細については、Prometheusの公式ドキュメントを参照してください。
これで、Prometheusがアプリケーション(prometheus-api-metrics)のメトリクスを収集しているはずです。
次に、Grafanaでこのメトリクス用のダッシュボードを作成し、メトリクスを可視化しましょう。
Grafanaには各ユースケースに応じたダッシュボードが有志により公開されており、これをそのまま利用またはカスタマイズすることでダッシュボード作成の手間を大幅に軽減できます。
prometheus-api-metrics向けのダッシュボードも公開されていますので、今回はこれを利用しましょう。
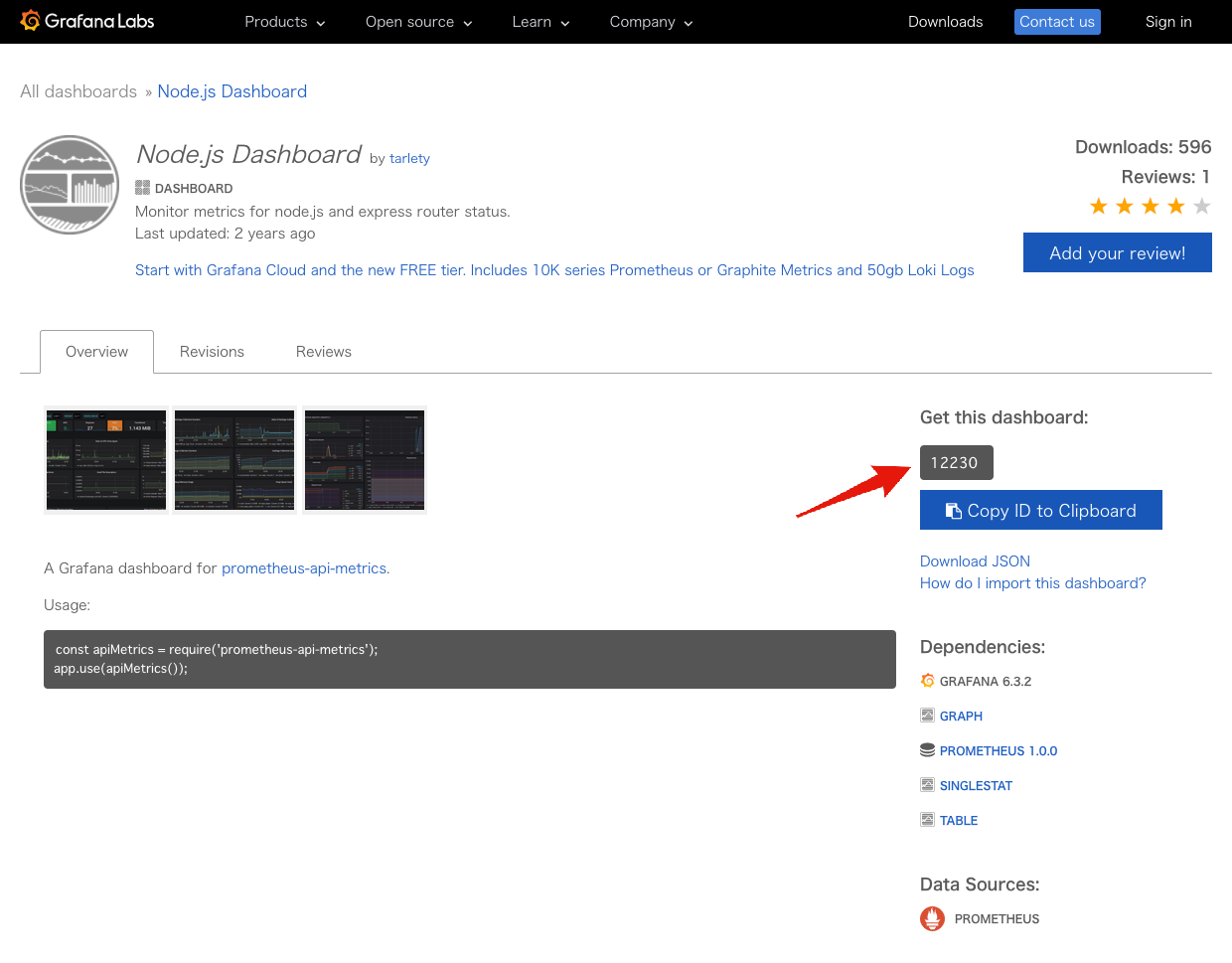
使い方は簡単です。上記のダッシュボードに付与されているIDをもとにダッシュボードをインポートするだけです。
Grafana UIのサイドバーからCreate -> Importを選択します。
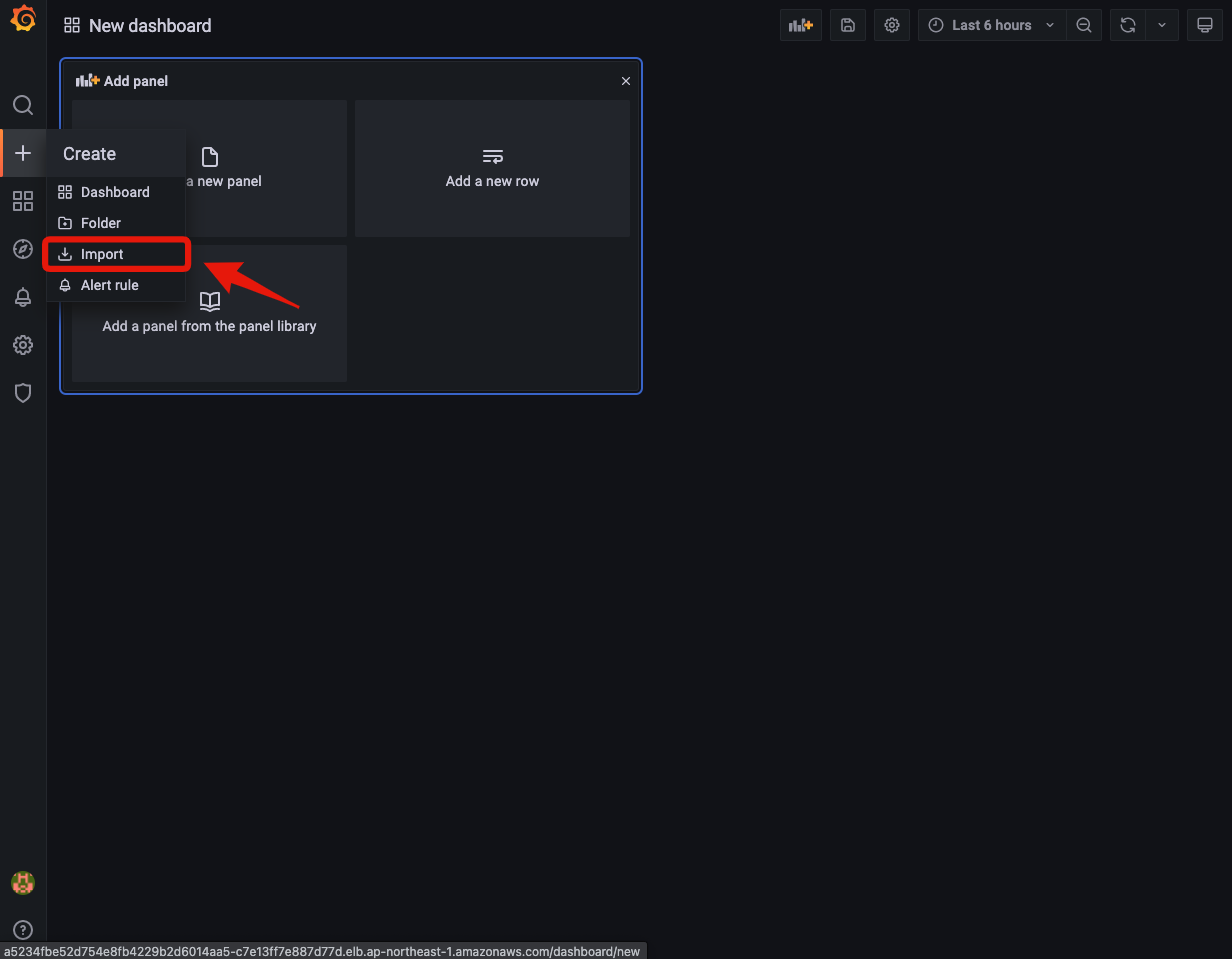
ダッシュボードのIDを入力し、Loadをクリックします。
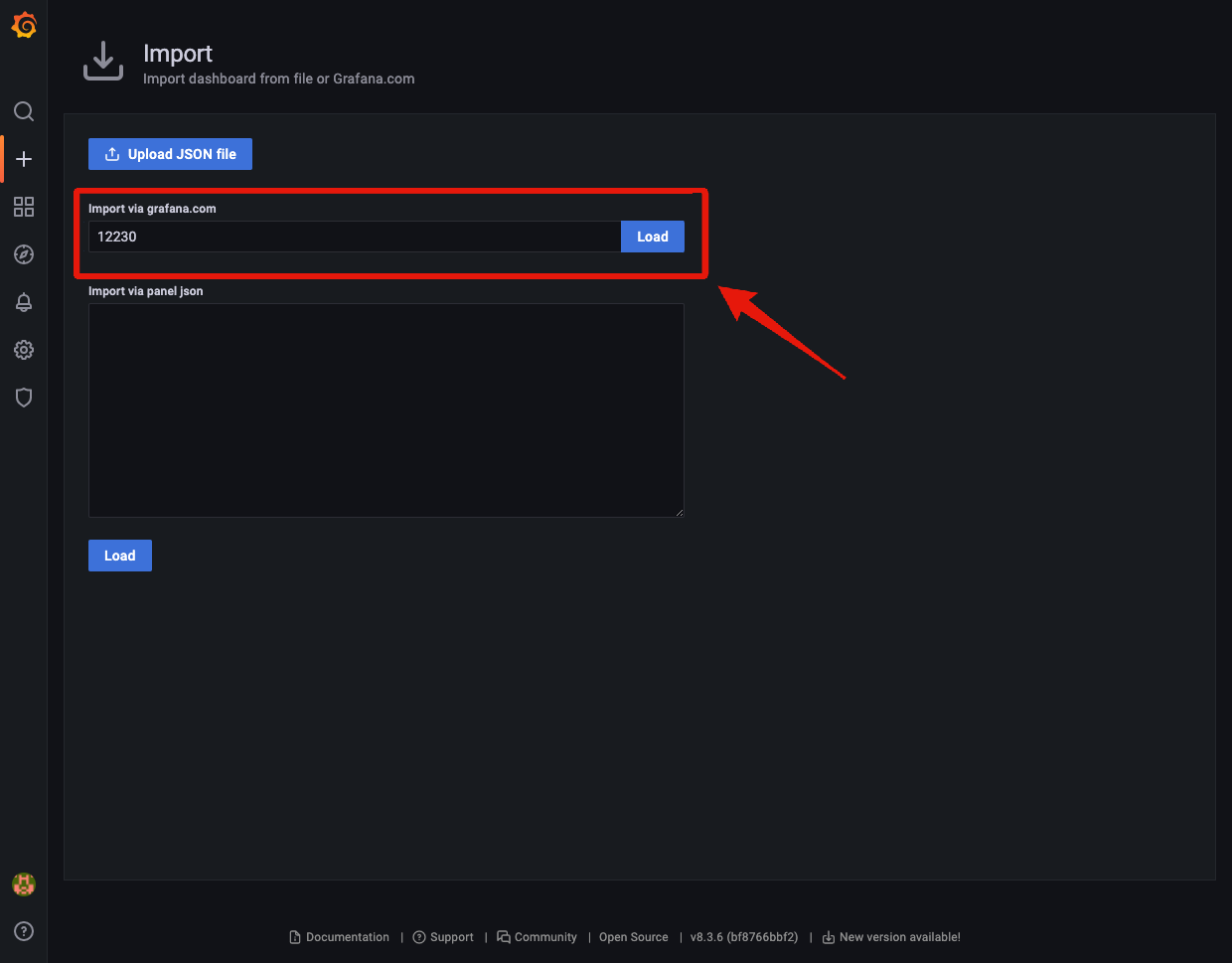
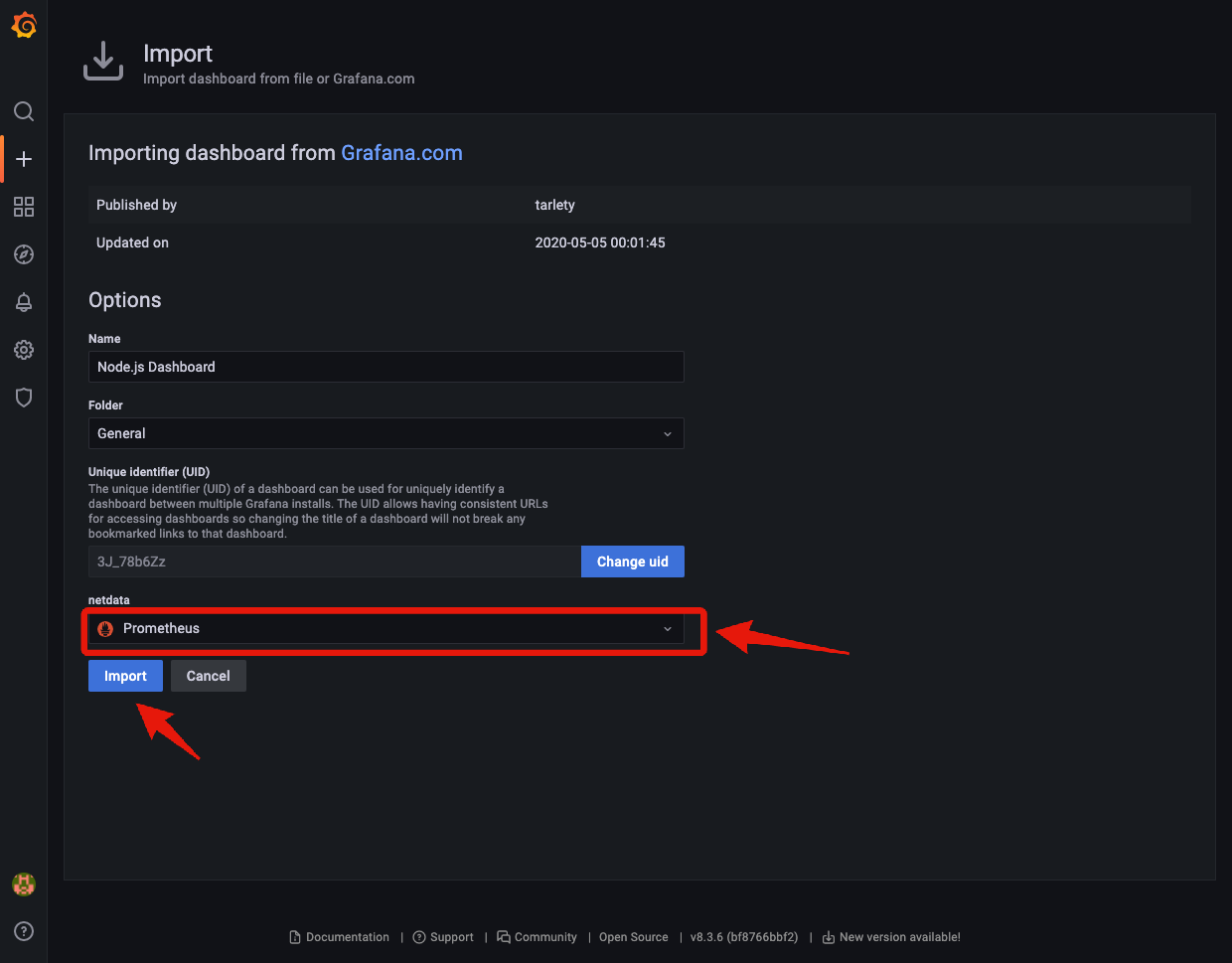
netdataにでPrometheusを選択し、Importをクリックすれば完成です(Name等は必要に応じて変更してください)。
次のようなダッシュボードが表示され、アプリケーションのメトリクスが表示されているはずです。
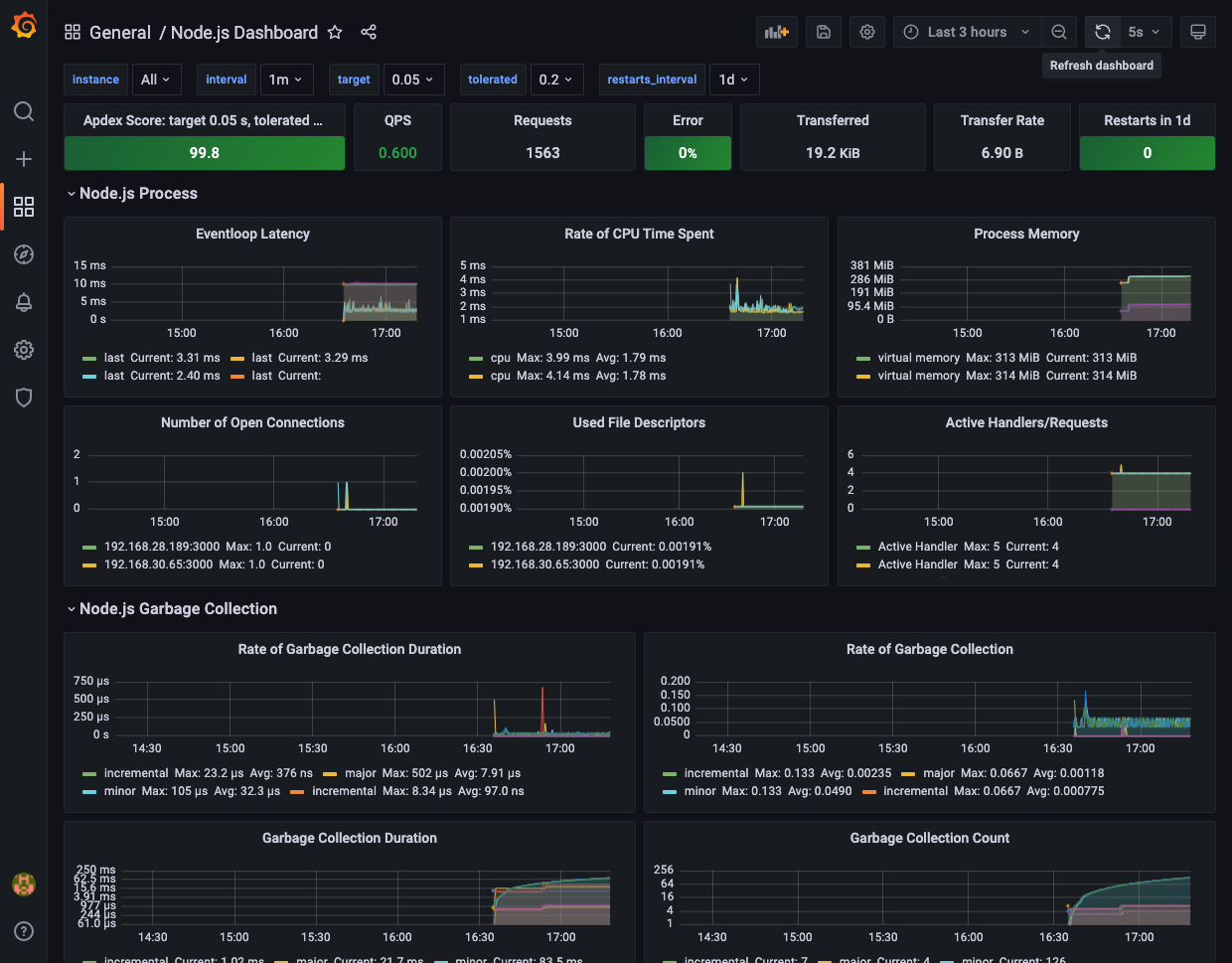
セットアップコードを除き、アプリケーションのロジックに手を入れることなく、アプリケーションメトリクスを収集、可視化できました。
ここでは実施しませんが、実際のプロジェクトでは、アプリケーションの特性にあったカスタムメトリクス収集やダッシュボード作成が必要なってくることも多いでしょう。
もちろんこれについても、PrometheusとGrafanaで対応可能です。
これには、アプリケーション内でカスタムメトリクスをPrometheusに公開し、Grafanaで可視化する必要があります。
アプリケーション側では、Prometheusのクライアントライブラリのprom-client[6]がありますので、これを利用してメトリクスの生成をします。これでメトリクスエンドポイントにカスタムメトリクスが追加で公開されます。
後は、Grafanaの方で、Prometheusクエリ言語のPromQLを使ってメトリクスを取得すれば、Grafanaの豊富な可視化機能を利用できます。
ダッシュボードで利用可能なパネルや作成方法は、以下公式ドキュメントを参照してください。
また、Grafanaの公式ドキュメントにダッシュボード作成ポリシーや成熟度レベルについて言及されていますので、こちらを合わせて参考にすると良いでしょう。
クリーンアップ
#kube-prometheus-stackはhelmコマンドでアンインストールしてください。
helm uninstall kube-prometheus-stack -n prometheus
それ以外のリリース削除については、以下を参照してください。
まとめ
#今回はPrometheusとGrafanaという鉄板の組み合わせで、メトリクス収集と可視化を行いました。
kube-prometheus-stackが必要な初期設定をあらかじめしてくれますので、簡単にリッチなUIが作成できるということが分かったと思います。
Prometheus自体は可視化やアラートだけではなく、オートスケーリング - Horizontal Pod Autoscaler(HPA)でも触れたように、オートスケールのメトリクスとしても利用可能です。
これをうまく使うことで、より利用するシステムの特性に適したスケーラビリティを手に入れることができるはずです。
また、ここでは触れませんでしたが、AWSはマネージドサービスとしてのPrometheusやGrafanaも提供しています。
こちらを採用する場合は、マネージドサービスで得られる可用性に加えて、サービス課金を自前で構築する場合の運用コストと比較して決定すると良いでしょう。
個人的な感覚ですが、近年はKubernetes Operatorの普及に伴って安定した運用が可能となり、両者に大きな差はなくなってきたのではと感じます。
一度自前で運用してみてから、マネージドサービスに切り替えるかを判断するのも良いと思います。
なお、Prometheusのマネージドサービスは、メトリクス量に応じて課金されますので、切替える場合は必要なメトリクスを絞るなどの工夫も必要になってくるでしょう。
参考資料
PrometheusもCNCFのホスティングプロジェクトでしたが、その成熟度からKubernetesに次いでGraduatedステータスとなりました。 ↩︎
類似のものとして、他にもkube-prometheusがありますが、現時点では開発中のステータスで安定していません。 ↩︎
もちろん実運用する場合は、カスタムドメインの設定とHTTPS化は必須になるでしょう。 ↩︎
PrometheusはPULL型のメトリクス収集を採用していますので、Prometheus側から定期的にメトリクスを取りに来ます。PUSH型の場合はアプリケーション側からメトリクスをモニタリングツールに送ります。 ↩︎
prom-clientは今回導入したprometheus-api-metricsにも依存関係として含まれています。詳細はprometheus-api-metricsの公式ドキュメントを参照してください。 ↩︎