RAGを利用して国会会議録に基づいて質問に回答するLLMを作る方法
はじめに
#こんにちは。デジタル戦略支援事業部の藤堂です。普段はデータ分析の業務に従事し、AI TECHチームでも活動をしています。
昨年末のChatGPTの登場以降、大規模言語モデル(LLM)の可能性が広く認識されるようになりました。これらのモデルは、インターネット上の膨大な情報を学習する能力を持っていますが、法律、医療などの専門的知識や、特定の企業や個人に関連する独自の情報には疎いのが現状です。このギャップを埋めるための技術として、Retrieval Augmented Generation (RAG)が注目を集めています。本記事では、RAGの基本的な仕組みを解説し、LlamaIndexを活用したRAGの実装方法について詳しく紹介します。
特に、本記事の焦点は、ChatGPTではなく、OpenなLLMを活用して、会議録などの回答生成を行うシステムの構築にあります。このアプローチを採用することで、機密性が高い社内文書に対しても、安全な環境下でLLMを活用した解析や回答生成が可能となります。これは、ビジネスの現場での情報活用を一段と進化させる可能性を秘めています。
RAGとは?
#そもそもLLMに新しい知識を回答してもらうにはどのようにすればよいでしょう?例えば、「2022年のNPBの日本選手権シリーズ優勝チーム」を答えてもらうにはどうすればよいでしょう?次のようにシンプルにChatGPTに尋ねてみます。
(入力)2022年のNPBの日本選手権シリーズ優勝チームは?
(回答)申し訳ございませんが、私の最後のトレーニングデータは2021年9月までのものですので、2022年のNPB(日本プロ野球)の優勝チームについての情報は持っていません。最新の情報を知りたい場合は、公式のNPBのウェブサイトやニュースサイトをご参照ください。
このようにChatGPTは2021年10月以降の知識がないため、回答することができません。そこで関連する情報をプロンプトの中に入力することが考えられます。次のプロンプトは、日本選手権シリーズ から関連部分をコピーしてきて質問文に含めました。
(入力)
64 2013年 楽天 初優勝 4 3 ● ○ ○ ● ○ ● ○ 巨人 星野仙一 美馬学 長野久義 Kスタ宮城
65 2014年 ソフトバンク 3年ぶり 6回目 4 1 ● ○ ○ ○ ○ 阪神 秋山幸二 内川聖一 R・メッセンジャー ヤフオクドーム
66 2015年 ソフトバンク 2年連続 7回目 4 1 ○ ○ ● ○ ○ ヤクルト 工藤公康 李大浩 山田哲人 神宮球場
67 2016年 日本ハム 10年ぶり 3回目 4 2 ● ● ○ ○ ○ ○ 広島 栗山英樹 B・レアード B・エルドレッド マツダスタジアム
68 2017年 ソフトバンク 2年ぶり 8回目 4 2 ○ ○ ○ ● ● ○ DeNA 工藤公康 D・サファテ 宮﨑敏郎 ヤフオクドーム
69 2018年 ソフトバンク 2年連続 9回目 4 1 1 △ ● ○ ○ ○ ○ 広島 工藤公康 甲斐拓也 鈴木誠也 マツダスタジアム
70 2019年 ソフトバンク 3年連続 10回目 4 0 ○ ○ ○ ○ 巨人 工藤公康 Y・グラシアル 亀井善行 東京ドーム
71 2020年 ソフトバンク 4年連続 11回目 4 0 ○ ○ ○ ○ 巨人 工藤公康 栗原陵矢 戸郷翔征 PayPayドーム
72 2021年 ヤクルト 20年ぶり 6回目 4 2 ● ○ ○ ○ ● ○ オリックス 高津臣吾 中村悠平 山本由伸 ほっともっとフィールド神戸
73 2022年 オリックス 26年ぶり 5回目 4 1 2 ● △ ● ○ ○ ○ ○ ヤクルト 中嶋聡 杉本裕太郎 J・オスナ 神宮球場
2022年のNPBの日本選手権シリーズ優勝チームは?
(回答)2022年のNPBの日本選手権シリーズの優勝チームは「オリックス」です。
上手く回答が返ってきましたね。
LLMに新たな知識を伝える方法として、関連情報をプロンプトに入力することが有効です。次に問題となるのは、どのようにしてプロンプトに関連情報を取得するのか、という点です。上記の例では、質問の答えが含まれるインターネット上の関連ページを人の目で探し出し、その中から必要な部分をプロンプトとして入力しました。しかし、この方法ではシステムとしてのスケーラビリティが低いことは明らかです。
そこで、文書が蓄積されたデータベースを構築し、検索(retrieval)を用いて関連文書を抽出、それをプロンプトに入力する仕組みが考えられます。これをRetrieval Augmented Generation(RAG)と呼びます。
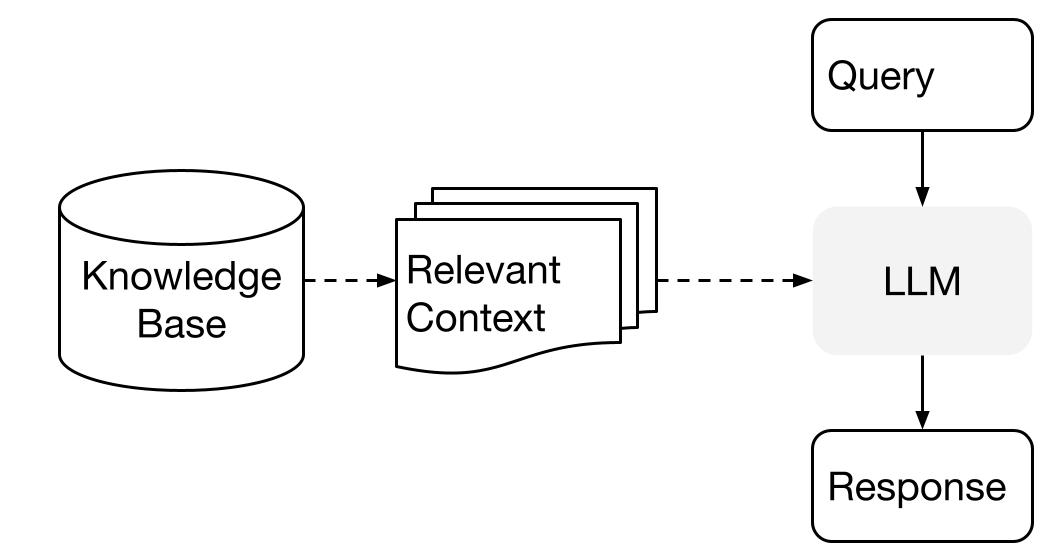
RAGの構成は上図の通りです。初めに、検索に使用したい全ての文書を言語モデルの埋め込みを利用してベクトル化し、このベクトルデータをベクトルDB(Knowledge Base)に蓄積します。次に、ユーザーからの質問文(Query)を同様にベクトル化します。このベクトル化された質問文とベクトルDB内の文書ベクトルとの類似度を計算し、質問文に最も関連する文書(Relevant Context)を選び出します。この選び出された文書は質問文と共にLLMに入力され、LLMが回答を生成します。
LlamaIndexを用いたRAGの利用
#ここからはLlamaIndexというPythonライブラリを使用し、RAGを実装する方法について説明します。今回、RAGを使用するにあたり、国会会議録APIから取得できるテキストデータを集めました。1947年までさかのぼって取得可能ですが、今回は2022年のデータを使用します。
以下のような発言者の発言単位ごとのデータです。
自由席もあるということで余り把握はできないということかもしれませんが、ただ、新幹線ってほとんどが指定席ですよね。
自由席はかなり混んでいるのに指定席はがらがらみたいなことが起こっていて、もっともっと指定席の方を例えば値段を下げるようにして皆さんが乗っていただく。
空気を運ぶんじゃなくて、もっと観光促進、そしてビジネス交流が図れるような料金設定をするということも、これは国交省の方でもっともっとJRを、けつをひっぱたくというか、そういう形でやはり促進をさせていただきたいというふうにも思っております。
そういうことで、新幹線においてダイナミックプライシング、飛行機なんかだともう当然なっているんですけれども、そういったことをもっと大胆に進めるようなお考えがないのかというのをお伺いしたいと思います。
(2022-10-28 会議録 衆議院 国土交通委員会 第2号 より)
このような発言が124,071件、文字数にして49,020,141個と、それなりの量のデータとなります。
Pythonと主要ライブラリのバージョンは次のようになります。とくにLlamaIndexやtransformersはバージョンの更新が早いので、これらのバージョンは意識しましょう。
Python 3.10.10
llama-index==0.8.22
transformers==4.31.0
accelerate==0.20.3
langchain==0.0.284
pydantic==1.10.12
まず埋め込み用のモデルと、文書生成に使用するLLMを別々に読み込みます。文書生成用のLLMとして今回、vicuna-13b-v1.5-16kを用います。このモデルはMeta社から公開されているLlama-2を対話用に学習した最大トークン数16KのLLMです。今回の検証に際し、他にもいくつかの公開LLMを試しましたが、このvicunaの生成品質が最もよかったです。RAGではどうしてもプロンプト数多くなるので、単純な日本語生成能力だけではなく、最大トークン数が影響する印象があります。埋め込み用のモデルはe5-base-multilingual-4096を用います。
ここで、LLMをマシン上で使用するために必要なメモリサイズについて触れておきます。vicunaの方は13bとあるように、130億のパラメータ数からなるLLMです。これらのパラメータの実体は数値であり、何バイトのデータ型として読み込むかによってLLMを使用するために必要なメモリサイズが変わります。単精度float32、すなわち4byteでモデルを読み込むと、13G×4byte=52GBが必要になります。同様に、半精度float16(2byte)だと26GB、モデルの量子化の方法としてint8やint4が開発されていますが、それぞれ13GB、6.5GBとなります。ただしこれらの数値は概算で、実際にメモリに載せようとすると誤差が生じます。推論をするだけであればこの程度のメモリサイズがあれば問題なく、推論速度は遅くなりますがCPUでも実行可能です。一方、LLMの学習をする場合、更にメモリが必要になります。
Processor (CPU): Intel(R) Xeon(R) Gold 5315Y CPU @ 3.20GHz, 8 Cores
Memory (RAM): 45GB
Graphics Card (GPU): NVIDIA RTX A6000 with 48GB VRAM
今回試用したマシンスペックは上記のようになります。VRAMが48GBあるため、以下では半精度でLLMを読み込んで使用します。
これ以降のコード記述の部分の説明は最低限とし、参考に参照記事のリンクを載せましたので、詳細を知りたい場合はそれらをご確認ください。
embed_model_name = "efederici/e5-base-multilingual-4096"
llm_model_name = "lmsys/vicuna-13b-v1.5-16k"
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
from langchain.embeddings import HuggingFaceEmbeddings
from llama_index import LangchainEmbedding
from typing import Any, List
# トークナイザーの初期化
tokenizer = AutoTokenizer.from_pretrained(
llm_model_name,
use_fast=True,
)
# LLMの読み込み
model = AutoModelForCausalLM.from_pretrained(
llm_model_name,
torch_dtype=torch.float16,
device_map="auto",
)
# パイプラインの作成
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=4096,
)
# LLMの初期化
llm = HuggingFacePipeline(pipeline=pipe)
# query付きのHuggingFaceEmbeddings
class HuggingFaceQueryEmbeddings(HuggingFaceEmbeddings):
def __init__(self, **kwargs: Any):
super().__init__(**kwargs)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return super().embed_documents(["query: " + text for text in texts])
def embed_query(self, text: str) -> List[float]:
return super().embed_query("query: " + text)
# 埋め込みモデルの初期化
embed_model = LangchainEmbedding(
HuggingFaceQueryEmbeddings(model_name=embed_model_name)
)
次にドキュメントを読み込みます。Congress_dataはフォルダとなっており、その下にhoge1.txt, hoge2.txt,...のような形でテキストファイルを配置しています。
from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
documents = SimpleDirectoryReader("Congress_data").load_data()
コールバック関数を準備します。内部のやりとりを確認しデバッグするにはこのコールバック関数を利用します。
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
llama_debug_handler = LlamaDebugHandler()
callback_manager = CallbackManager([llama_debug_handler])
プロンプトの文面を調整します。デフォルトではプロンプトの予約文に英語が使われており、しばしばLLMが英語で回答してしまうことがあります。以下のように設定をすることで日本語で回答しやすくなります。設定は、こちらを参考にさせていただきました。
from llama_index.llms.base import ChatMessage, MessageRole
from llama_index.prompts.base import ChatPromptTemplate
# QAシステムプロンプト
TEXT_QA_SYSTEM_PROMPT = ChatMessage(
content=(
"あなたは世界中で信頼されているQAシステムです。\n"
"事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。\n"
"従うべきいくつかのルール:\n"
"1. 回答内で指定されたコンテキストを直接参照しないでください。\n"
"2. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。"
),
role=MessageRole.SYSTEM,
)
# QAプロンプトテンプレートメッセージ
TEXT_QA_PROMPT_TMPL_MSGS = [
TEXT_QA_SYSTEM_PROMPT,
ChatMessage(
content=(
"コンテキスト情報は以下のとおりです。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"事前知識ではなくコンテキスト情報を考慮して、クエリに答えます。\n"
"Query: {query_str}\n"
"Answer: "
),
role=MessageRole.USER,
),
]
# チャットQAプロンプト
CHAT_TEXT_QA_PROMPT = ChatPromptTemplate(message_templates=TEXT_QA_PROMPT_TMPL_MSGS)
# チャットRefineプロンプトテンプレートメッセージ
CHAT_REFINE_PROMPT_TMPL_MSGS = [
ChatMessage(
content=(
"あなたは、既存の回答を改良する際に2つのモードで厳密に動作するQAシステムのエキスパートです。\n"
"1. 新しいコンテキストを使用して元の回答を**書き直す**。\n"
"2. 新しいコンテキストが役に立たない場合は、元の回答を**繰り返す**。\n"
"回答内で元の回答やコンテキストを直接参照しないでください。\n"
"疑問がある場合は、元の答えを繰り返してください。"
"New Context: {context_msg}\n"
"Query: {query_str}\n"
"Original Answer: {existing_answer}\n"
"New Answer: "
),
role=MessageRole.USER,
)
]
# チャットRefineプロンプト
CHAT_REFINE_PROMPT = ChatPromptTemplate(message_templates=CHAT_REFINE_PROMPT_TMPL_MSGS)
それ以外の設定をします。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index.node_parser import SimpleNodeParser
from llama_index import ServiceContext
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
tokenizer,
chunk_size=4096-3,
chunk_overlap=20, # オーバーラップの最大トークン数
separators=["\n= ", "\n== ", "\n=== ", "\n\n", "\n", "。", "「", "」", "!", "?", "、", "『", "』", "(", ")"," ", ""],
)
node_parser = SimpleNodeParser(text_splitter=text_splitter)
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
callback_manager=callback_manager,
)
以下を実行することでシステムを動作させるための埋め込みなどの処理が走ります。ドキュメント数が多い場合、それなりの時間がかかります。
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)
# クエリエンジンの準備
query_engine = index.as_query_engine(
similarity_top_k=3,
text_qa_template=CHAT_TEXT_QA_PROMPT,
refine_template=CHAT_REFINE_PROMPT,
)
以上でRAGを実行するための設定が完了したので、実際に試してみましょう。以下のquestionsの中に質問内容を記述することで、回答が得られます。
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.WARNING, force=True)
import torch
def query(question):
print(f"Q: {question}")
response = query_engine.query(question).response.strip()
print(f"A: {response}\n")
torch.cuda.empty_cache()
questions = [
"城郭保護にかかる予算は?",
"デジタル田園都市国家構想の目的は?",
"日本の難民認定率は?",
"子供の勉強にデジタル技術を導入することのデメリットは?",
"令和二年十月の東京外環の陥没の原因は?"
]
for question in questions:
query(question)
次のような回答が返ってきます。
Q: 城郭保護にかかる予算は?
A: 近世城郭の保護にかかる予算は、令和三年度で約23億円、直近5年間の平均で年間約20億円程度です。この予算は、国庫補助による支援として文化庁が実施しています。また、会場外の警備に関しては、既定予算に計上されており、警備や警察上の予算に含まれています。
Q: デジタル田園都市国家構想の目的は?
A: デジタル田園都市国家構想の目的は、地方の課題をデジタル技術を活用して解決し、地域の個性を生かしながら地方を活性化し、持続可能な経済社会を目指すことです。地方におけるデジタル技術の積極的な活用によって、稼ぐ地域や仕事を創出し、地域経済の発展につなげることができます。この構想は地方に焦点を当てた取組であり、地方創生と密接に関連しています。
Q: 日本の難民認定率は?
A: 日本の難民認定率は、提供されたコンテキスト情報によれば、〇・四%です。ただし、難民認定率を単純に比較することは相当ではないとされています。難民認定には、各国の事情が異なるため、それぞれの国の状況に応じて適切に判断されるべきです。
Q: 子供の勉強にデジタル技術を導入することのデメリットは?
A: 子供の勉強にデジタル技術を導入することにはいくつかのデメリットがあります。
1. 視力の低下: スマートフォンやタブレットなどのデバイスを使用すると、子供たちの視力が低下する懸念があります。
2. 睡眠障害: 子供たちがデバイスを使用すると、睡眠時間や質の低下が起こることがあります。
3. 社会性や感受性の低下: デジタル技術に没頭することで、子供たちの社会性や感受性が低下する可能性があります。
4. いじめやメンタルヘルスの問題: デジタル技術を使用することで、いじめやメンタルヘルスの問題が引き起こされることがあります。
5. 知能の低下: デジタル技術を過剰に利用することで、子供たちの知能が低下する可能性があります。
これらのデメリットに対処するために、教育現場ではデジタル技術の適切な活用や、適切なルールの設定、保護者との連携などが重要です。また、文部科学省が実施しているデジタル教科書の実証研究において、教育上の効果や健康面への影響を含めた定量的な分析が行われることが望ましいです。
Q: 令和二年十月の東京外環の陥没の原因は?
A: 令和二年十月に発生した東京外環事業、関越-東名間の陥没、空洞事故の原因については、特殊な地盤条件下においてシールドカッターが回転不能になる閉塞を解除するために行った特別な作業に起因するシールドトンネルの施工にあることが確認されています。
自然な日本語で回答が返ってきます。どのような関連文書を参照しているかについては、以下のようにコールバック関数を使って確認できます。
from llama_index.callbacks import CBEventType
llama_debug_handler.get_event_pairs(CBEventType.LLM)[0][1].payload

出力結果は上図のようになり、「予約文」「関連文」「質問文」「回答文」から構成されます。ここで与えた質問は具体的な発言録から考えたのですが、大量の文書があるにもかかわらず、狙った関連部分をうまく検索できていることが分かりました。また回答文の生成もうまく必要な部分を取り出して文章を生成しているようです。中には「あなたが提供したコンテキスト情報によれば」のように予約文で除外したい文節が含まれるケースもありました。
おわりに
#今回、RAGを使用して会議録の内容に基づく回答システムを構築しました。公開されているLLMを使用した結果、違和感のない日本語での回答が得られました。確認した範囲での回答の品質には特に問題は見当たりませんでした。ただ、国会会議録は特定の知識に特化していない上、一次情報源でもないため、QAシステムのデータとしては最適ではないかもしれません。しかし、RAG自体はデータや活用方法によって、多岐にわたる可能性を持つ技術であると感じました。